DeepFaceLab参数详解之遮挡神器FAN-X
DeepFaceLab参数详解之FAN-X。
用DeepFaceLab做出如假包换的换脸视频已经不是什么新鲜事儿,即便你不会,但是肯定看过很多不错的换脸视频。但是,观察大部分视频你可以发现一个共同点,就是这些视频基本脸部都“很干净”。很干净的意思就是脸上几乎没有遮挡。很少看到那些戴眼镜,头发或手挡住脸的。之所以会这样,是因为软件对于遮挡的处理能力并不是很强,但是也并不是说完全没法处理。今天就来说一个参数FAN-X,可以处理一些简单的遮挡。
FAN-X简介
Fan-x是DeepFaceLab转换(convert)环节的一个参数,名字是:Mask mode。这个参数于20190321版本加入,仅针对SAE,DF等全脸模型。后来有经过多次修改,直到827版本,H128等半脸模型也可以使用这个参数了。
FAN-X使用
下面我以907版的H128为例演示一下遮挡的具体使用过程。

我这里已经准备好了一个高迭代的模型,并且把之前训练模型之前的步骤全部做了一遍。data_dst中特地挑选了几张有遮挡的图片,这些图片来自官方的demo,大家也可以很容易的跟着操作。
万事俱备后,点击7) convert H128.bat 开始转换。转换启动后启用动态交互,然后按Tab键盘进入预览窗口。
默认情况下,可以很清楚的看到,希亚·拉博夫的手指被托尼的脸给覆盖了。这显然不是我们要的结果。我们希望的是手指能露出来,但是脸是托尼的。
此时,只需要按键盘上的X两次,将遮罩模式(Mask mode)切换成 Fan-dst

Magic ….可以非常清楚的看到,手指出来了,脸往后贴了。这可不是我PS的哦~~~~

稍微调整一下其他参数后最终效果如上。同理,其他遮挡也可以这样处理。
单纯从这个例子来说,遮挡处理已经非常不错,但是实际应用可能没这么理想,因为Fan模式的效果直接受Fan模型的影响,因为fan模型中已经训练了官方demo中的遮挡,所以转换的时候直接使用就效果很好。而作者提供的Fan模型训练的数据非常有限,所以能力也比较有限,如果真的要处理所有奇奇怪怪的遮挡,就必须自己训练Fan。这个就不展开了,对于小白来说先学会怎么用,然后再去考虑怎么优化。
FAN-X背后的原理。
知其然而不知其所以然总是让人很难受,尤其是作为一个程序员。下面我就来简单说说这背后的原理,这一部分内容不适合小白,深度学习方向的程序员可以一战,发际线越高战斗力越强O(∩_∩)O。
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
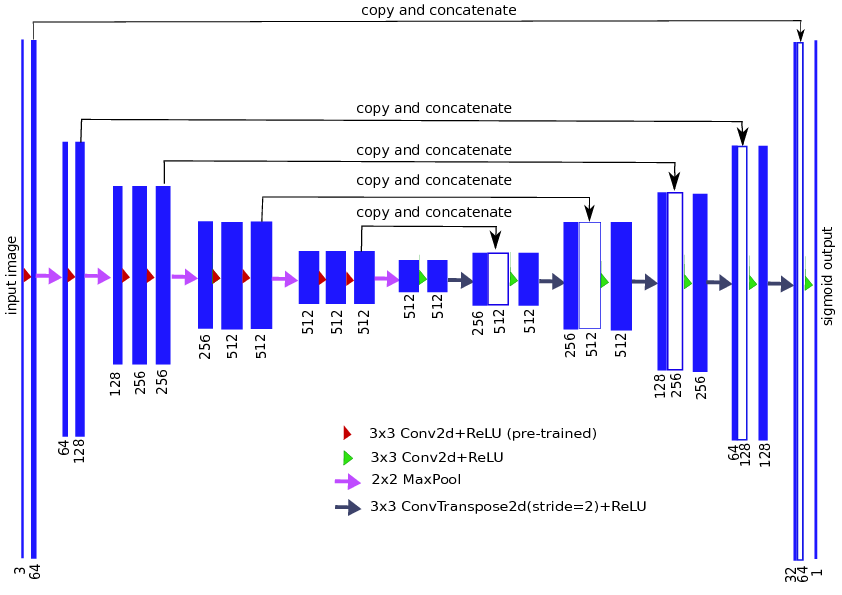
大概意思是,这是一个使用Vgg11编码器的U-NET网络,使用ImageNet进行了预训练,主要应用于图像分割。至于什么是Vgg11, 什么是U-NET,什么是ImageNet,这个…在下告退了。
开源项目地址:
https://github.com/ternaus/TernausNet
论文地址:
https://arxiv.org/abs/1801.05746


大佬,现在用的0620,除了这个版本,支持Fanx的H128的哪个版更稳定些?
quick96
Fan X 在Colab 中如何用🙏🏻
一样用啊。合成的时候可以选参数!
我覺得效果很不錯耶,H128在實際轉換時(非官方demo)選用learned*FAN-dst可以有效處理遮擋,成功率感覺有80%以上,出乎我意料的有用。您提到FAN-X是要特別訓練的,若是這樣對於非官方demo效果應該不會太好才是,我感到有點困惑?還是FAN-X是個即時運算出結果的演算法,不需訓練呢?
不是即时的,也是需要训练的!
问下 这个需要一个一个去赛选吗? 能不能只能识别被遮挡的部分, 一次要弄几千张图片 根本不可能手动一个一个去修改
您好.請問一下.
我用SAEHD訓練…src有眼鏡.dst也有眼鏡.合成時…(3) seamless..(7) learned*FAN-dst.其他Default.
(7) learned*FAN 遮擋.連dst的眼鏡都幫你畫上去了.這樣正常嗎?
有什麼設定.不要讓dst的眼鏡.覆蓋src的眼鏡呢?