2019年9月25日
DeepFaceLab错误,921版out of memory的解决方法。
OOM是DeepFaceLab非常常见的错误,一般发生在训练环节,起因是显存不足(不是内存)。但是有部分群友发现,自己明明有8G,11G的显存,但是依旧提示out of memory。奇怪的是,错误一直出现,训练可以继续。关于这个问题,因为本人的卡是10系列,无法验证,所以一直没有找到解决方法,近期有群友又问到这样的问题,我终于确定了解决方案,给大家分享一下。
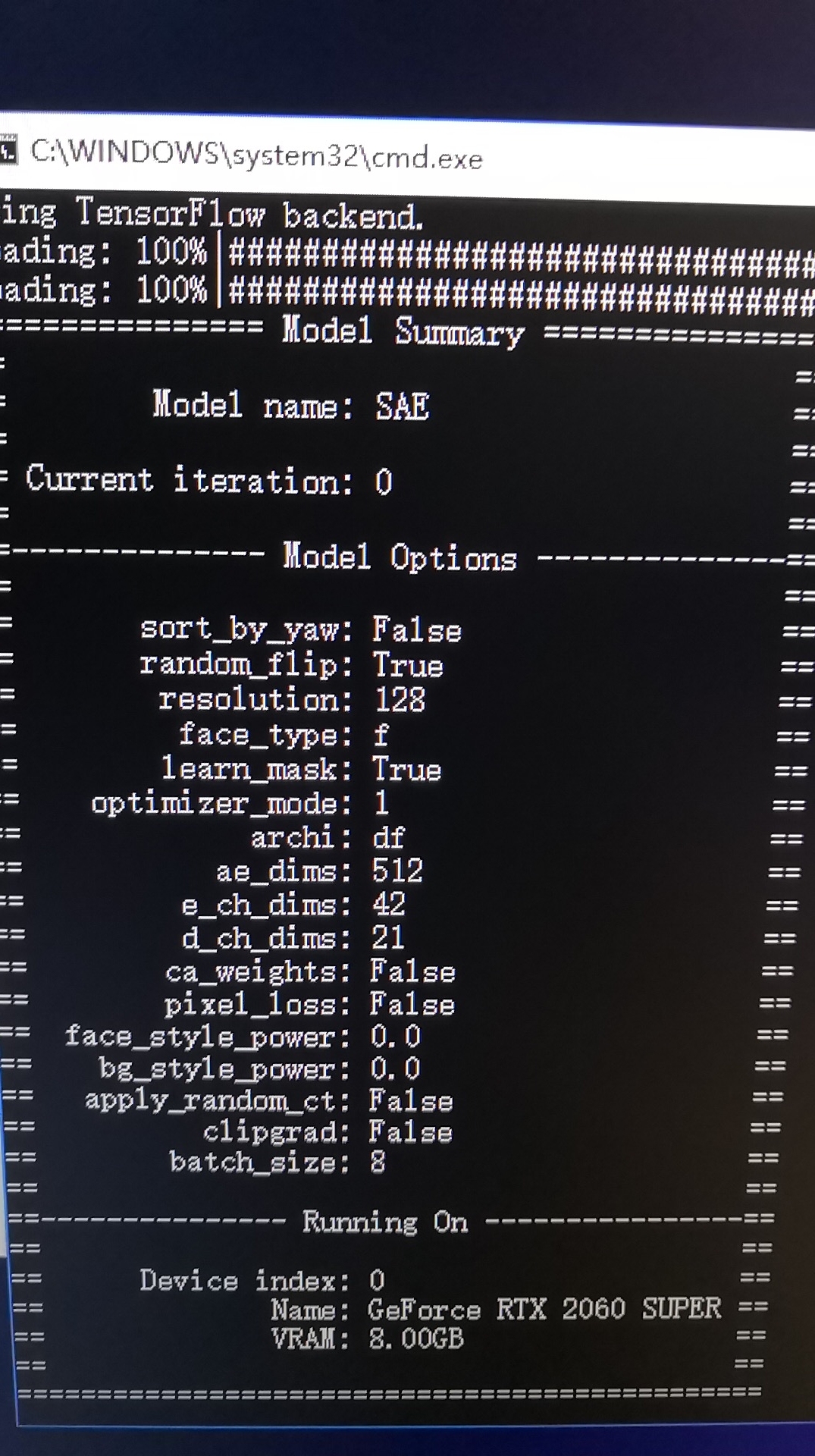
问题描述:
首先,这个错误主要发生在GeForce RTX 2060 Super, 2080Super 等20系列的显卡。是否跟Super有关,我没有确认过。
其次,620以及之前版本没有问题,827,907,921等版本似乎都存在这个问题。
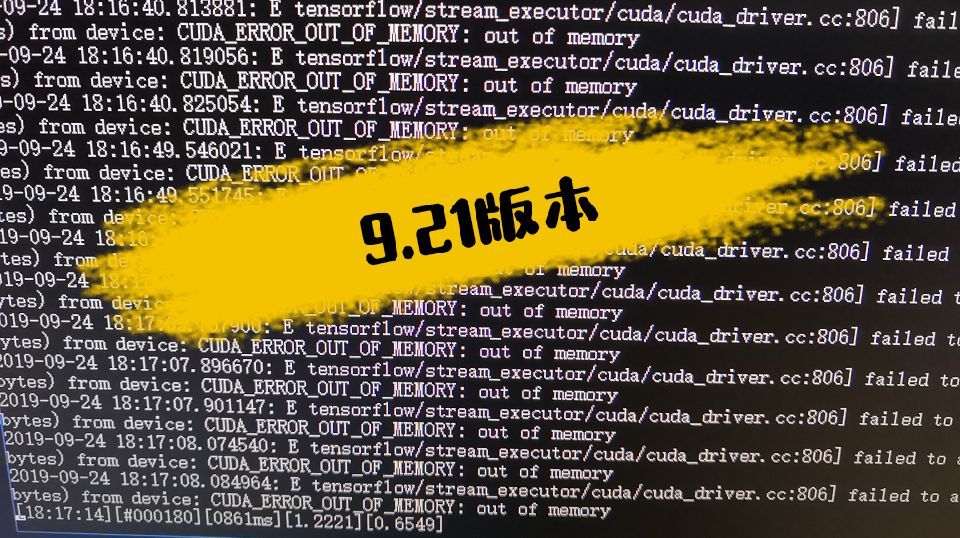
错误出现在训练环节,训练启动后出现如上图的提示failed to …. CUDA_ERROR_OUT_OF_MEMORY:out of memory. 每刷新一条loss记录,就出现一次。
解决方法:
其实,如果你是一个比较关注DeepFaceLab的github项目的人,应该很早就看到过如下的一个信息。
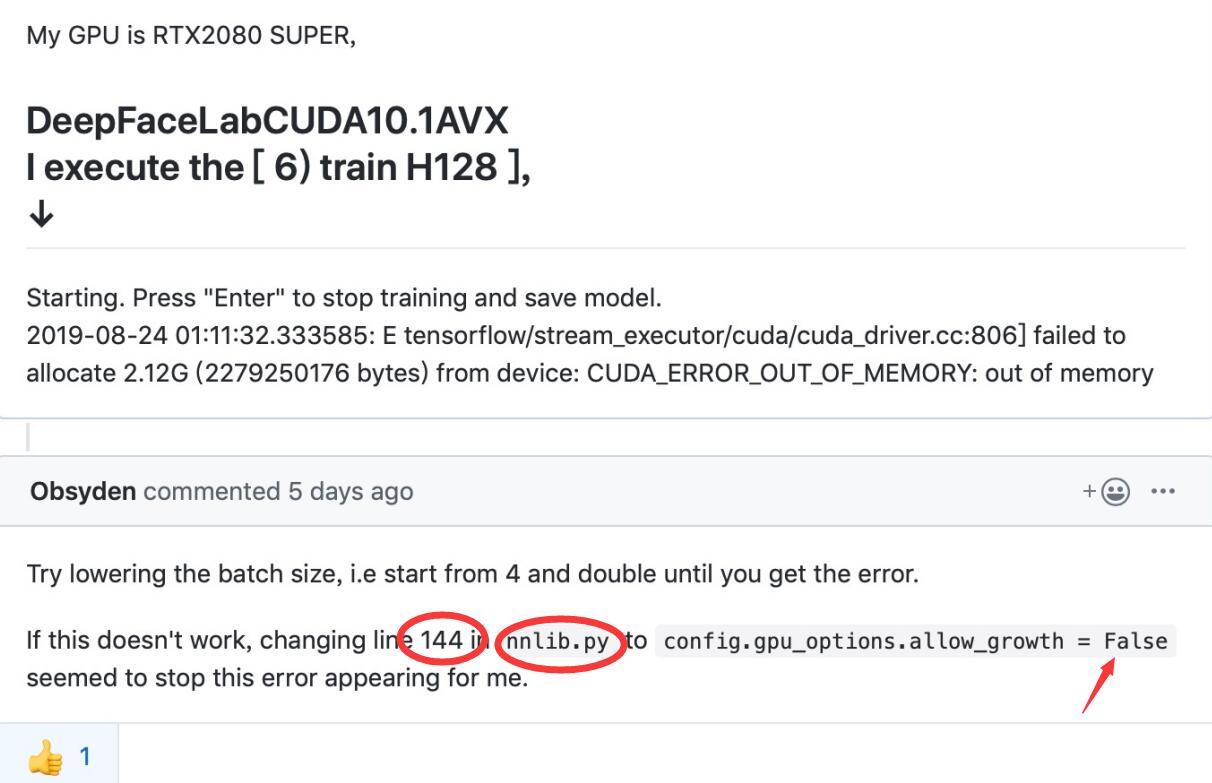
这条issue其实已经提出了解决方案。 图片中大概说的是,有一个人用的是RTX2080 Super 然后遇到了out of memory的问题。 然后,下面有人提供了一个解决方案。方案就是修改nnlib.py文件中144行,将True改为False
nnlib.py 具体路径为:…\_internal\DeepFaceLab\nnlib\nnlib.py
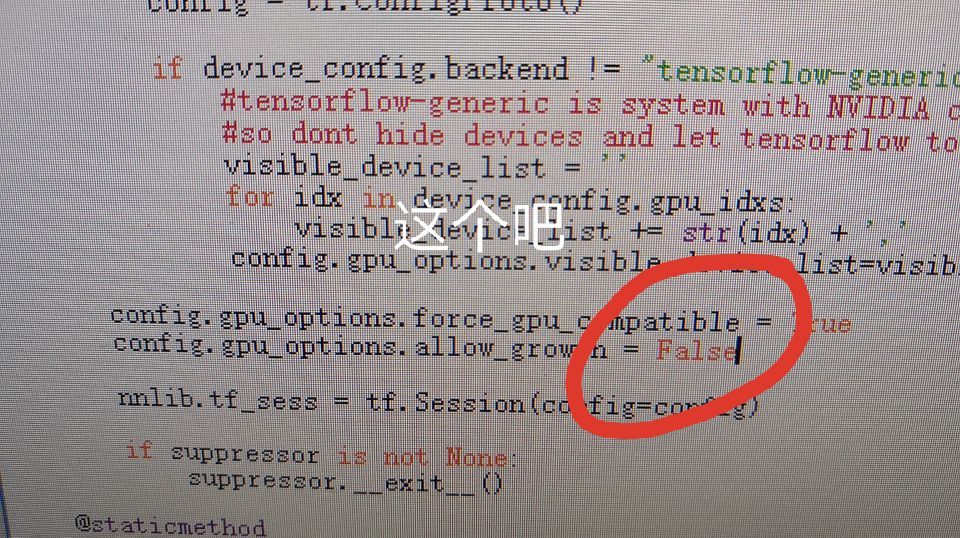
上图为群友的实况截图^_^~ 记住修改源代码不推荐用系统自带的记事本,用Notepad++等工具会比较好。
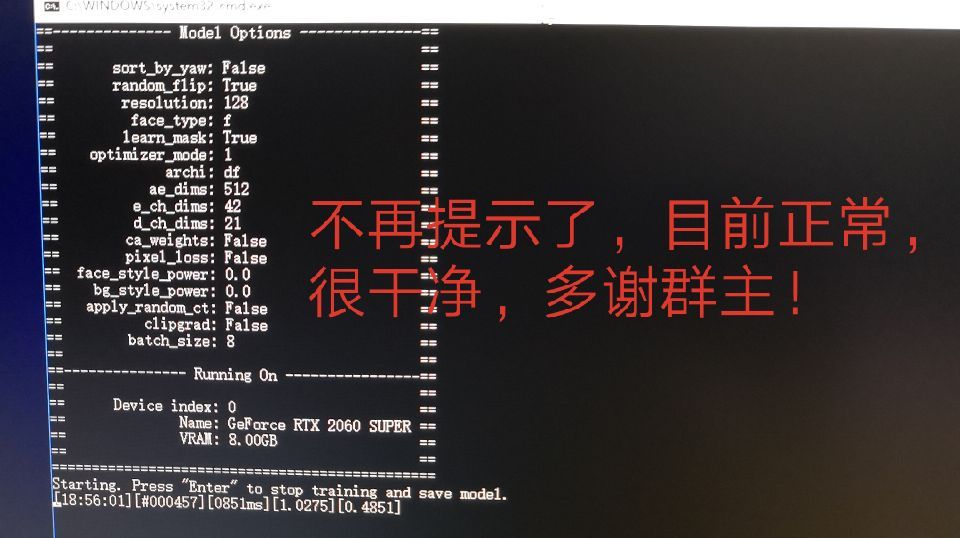
修改完成后,保存,再次开始训练。此时,已经不再异常提示,整个界面干净舒服了很多。



关于作者
tony
22 Comments
话说老大们现在主用sae还是H128?
H128
话说大佬们都不用SAE的吗?
5) data_dst extract faces MANUAL RE-EXTRACT DELETED RESULTS DEBUG,手动提取脸部工具没有出现图片窗口 很奇怪,
第六步的时候不管H64还是H128还是其他 都是没有预览窗口出现,等了几个小时还是不出现,英文已经显示starting,press enter to stop training and save model 就是不出现预览窗口
手动提取的前提是,需要删除debug中的需要重新提取的图片。
如果在google colab,要如何修改呢??
老大这个错误怎么破?
ValueError: cannot convert float NaN to integer
感觉是哪里缺少图片!
都是默认设置
Starting. Press “Enter” to stop training and save model.
INFO:plaidml:Analyzing Ops: 8 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 221 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 321 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 376 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 457 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 608 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 692 of 1559 operations complete
INFO:plaidml:Analyzing Ops: 856 of 1559 operations complete
ERROR:plaidml:unable to run OpenCL kernel: CL_MEM_OBJECT_ALLOCATION_FAILURE
[09:03:07][#000001][38.25s][0.0000][0.0000]
INFO:plaidml:Analyzing Ops: 138 of 159 operations complete
INFO:plaidml:Analyzing Ops: 138 of 159 operations complete
E:\20190620\DeepFaceLabOpenCLSSE\_internal\DeepFaceLab\models\ModelBase.py:595:
RuntimeWarning: invalid value encountered in double_scalars
ph_max = int ( (plist_max[col][p] / plist_abs_max) * (lh_height-1) )
Traceback (most recent call last):
File “E:\20190620\DeepFaceLabOpenCLSSE\_internal\DeepFaceLab\main.py”, line 25
4, in
arguments.func(arguments)
File “E:\20190620\DeepFaceLabOpenCLSSE\_internal\DeepFaceLab\main.py”, line 13
4, in process_train
Trainer.main(args, device_args)
File “E:\20190620\DeepFaceLabOpenCLSSE\_internal\DeepFaceLab\mainscripts\Train
er.py”, line 283, in main
lh_img = models.ModelBase.get_loss_history_preview(loss_history_to_show, ite
r, w, c)
File “E:\20190620\DeepFaceLabOpenCLSSE\_internal\DeepFaceLab\models\ModelBase.
py”, line 595, in get_loss_history_preview
ph_max = int ( (plist_max[col][p] / plist_abs_max) * (lh_height-1) )
ValueError: cannot convert float NaN to integer
[09:03:17][#000146][0015ms][1.0000][1.0000]
我也是这个问题,用SAE就可以。有大佬解答一下吗?
你好,请问下训练时候没有显卡型号显示,下面有个警告写着只运行2GB GPU,跑的H128,这是版本的问题吗?
能跑,就可以忽略这个提示。
站长大神我咨询一个事情,就是HH128合成图片的时候合成出来的新脸的皮肤质感和原素材的皮肤质感以及颜色光泽度基本一模一样,而DF合成图片就做不到,请问DF需要调节什么能达到H128默认合成就能达到的效果呢?
你好,请问你我是GTX 1080 3GB的显卡,用H64以及原始视频,默认batch size 4,nnlib.py也改了,还是OOM错误。可能是哪里的问题呢?
1080 不是8G么? 1050才是3G吧。 3G只能跑H64轻量级。启用轻量级就不会OOM了。
站长,请问如果我有一个100W的MODEL,我用这个MODEL训练一个新的人脸,训练时候batch-size设置成4是不是最快的方式
一般来说是bs低一点会更快。
记得刚玩的时候,他们都说bs是清晰度的意思,越大就越清晰,难道不是吗,?、减小bs并不会影响清晰度?
记得刚玩的时候,他们都说bs是清晰度的意思,越大就越清晰,难道不是吗,?、减小bs并不会影响清晰度?
batchsize在机器学习里是单词训练规模的意思。表示一次用n张图进行训练。假设整个数据集有1000张图片,如果一次训练1000张,可能遇到局部最优解,如果一次训练一张,那么结果可能不停波动不收敛,于是就有了batchsize,batchsize就是一次训练张数。迭代一轮的训练次数就是图片数/batchsize,训练轮数一般较epochs
1070ti 8g的,训练过程中常常无故停止,显卡突然就没占用了,这是什么原因
有什么提示么?