DeepFaceLab2.0 :超详细入门教程!
在这出门慌得一B,在家闲的D疼的日子,静下心来玩玩换脸黑科技也是一个不错的选择。新年新气象,DFL也迎来了2.0版本,虽然当前作者还在不断的修bug, 但是很多小伙伴肯定已经迫不及待的要去尝试新版本了。
今天我就针对2.0版本写一个详细的入门教程,争取做到只要会电脑的就能学会。话不多少直接进入正题,演示的软件版本为当天新鲜出炉的20200203版!
1. 获取软件以及安装
软件获取方法:
QQ群:659480116
或者作者GITHUB:https://github.com/iperov/DeepFaceLab
单击Extract开始解压软件。
软件安装本质上只是解压而已,无需安装,就像很多绿色软件一样。如果QQ管家或者360报毒(都是流氓软件),添加信任放行即可。
依赖安装:依赖的意思就是使用这个软件之前必须要先安装的软件,DFL的唯一依赖就是显卡驱动。所以你只需要更新驱动即可使用此软件,CUDA和CUDNN不是必须的。
2. 目录介绍
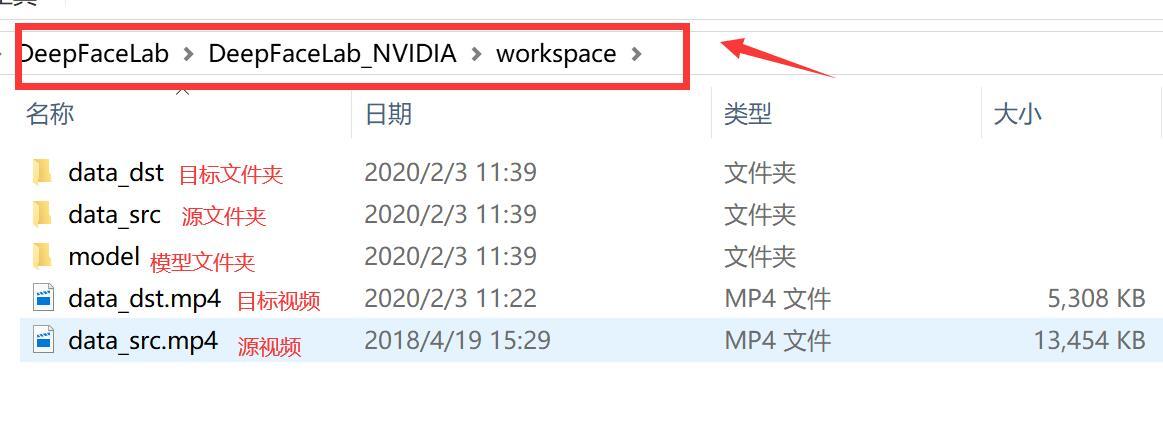
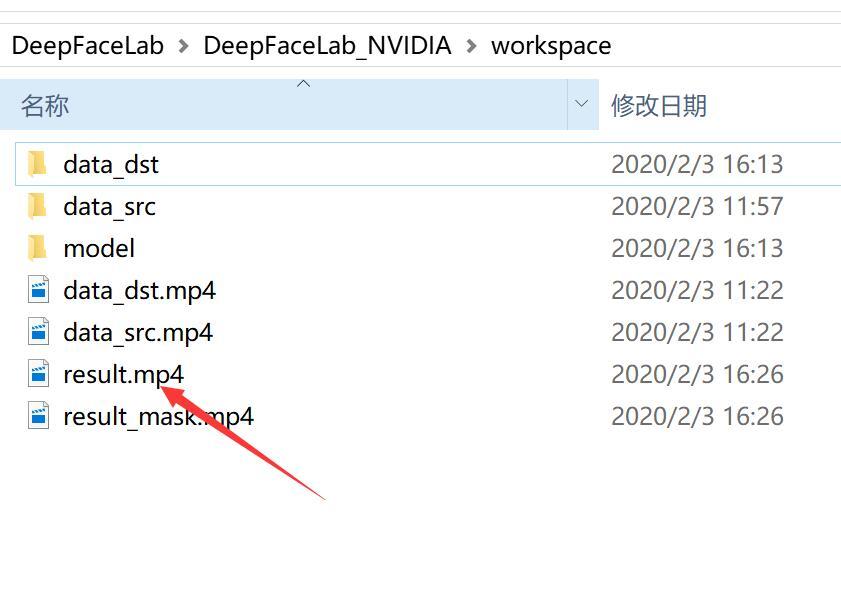
软件解压完成后会出现一个叫DeepFaceLab_NVIDIA的文件夹,里面有一个workspace,我们需要的文件都会在这里。这个文件夹下面有三个文件,两个视频,代表的意义如上图! 需要换自己的视频,只需要把这两个MP4换成自己的就好了。
软件运行过程中,在Data_dst 和data_src 中里面还会产生一个aligned的文件,里面会放置提取到的人脸图片,比较重要!
3. 流程介绍
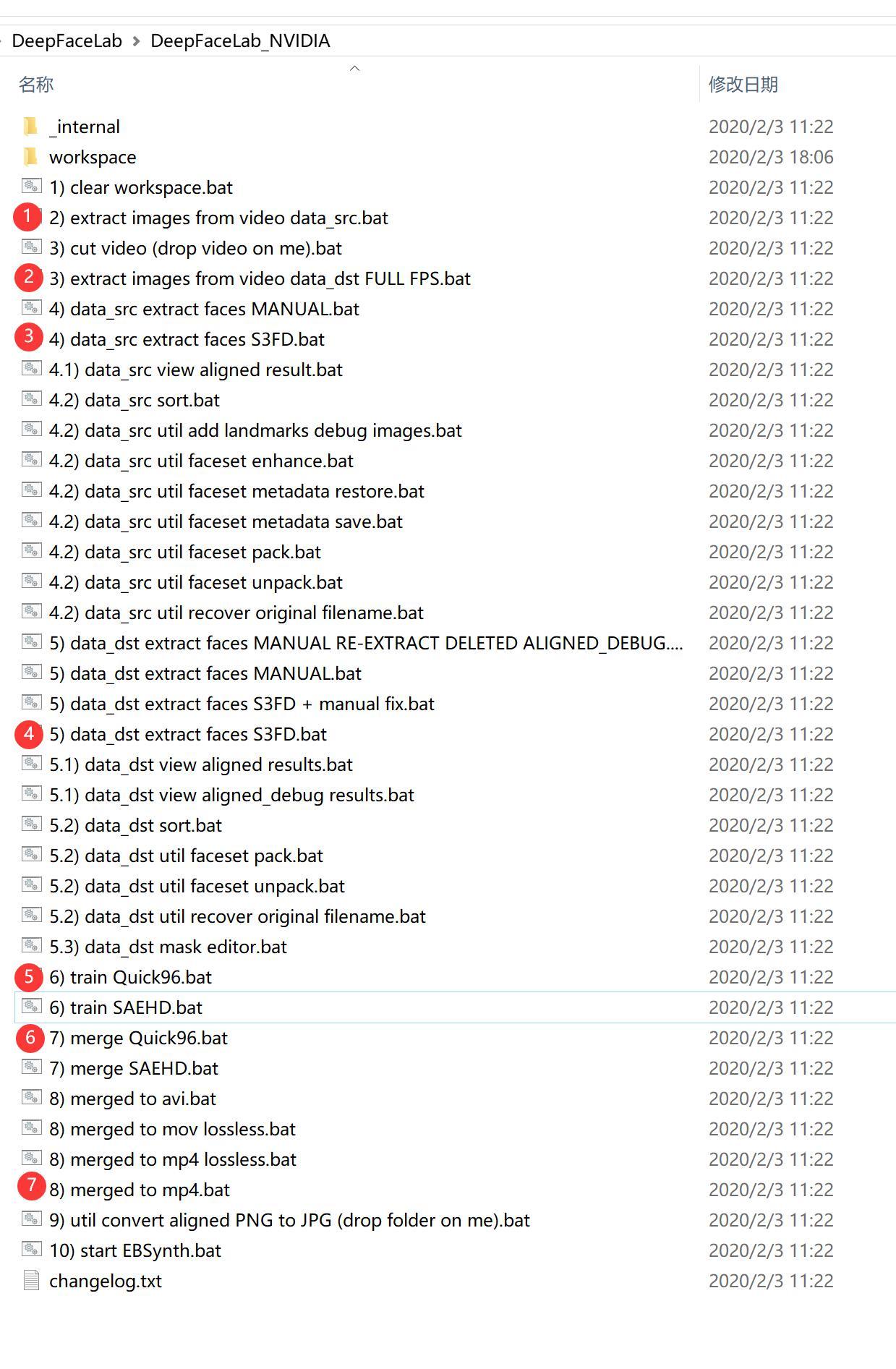
进入软件目录后会发现很多以.bat结尾的文件,叫批处理文件。此类文件在window系统下可以直接双击运行,和exe没有两样了。大致步骤如上。
软件使用的大概流程是:
1. 把视频转成图片
2. 从图片中提取头像
3. 用头像训练模型(模型相当于…..)
4. 用训练好的模型实现图片换脸
5 . 把换好脸的图片合成视频!
搞定。
具体的流程如下:
2) extract images from video data_src.bat (把源视频拆分成图片)
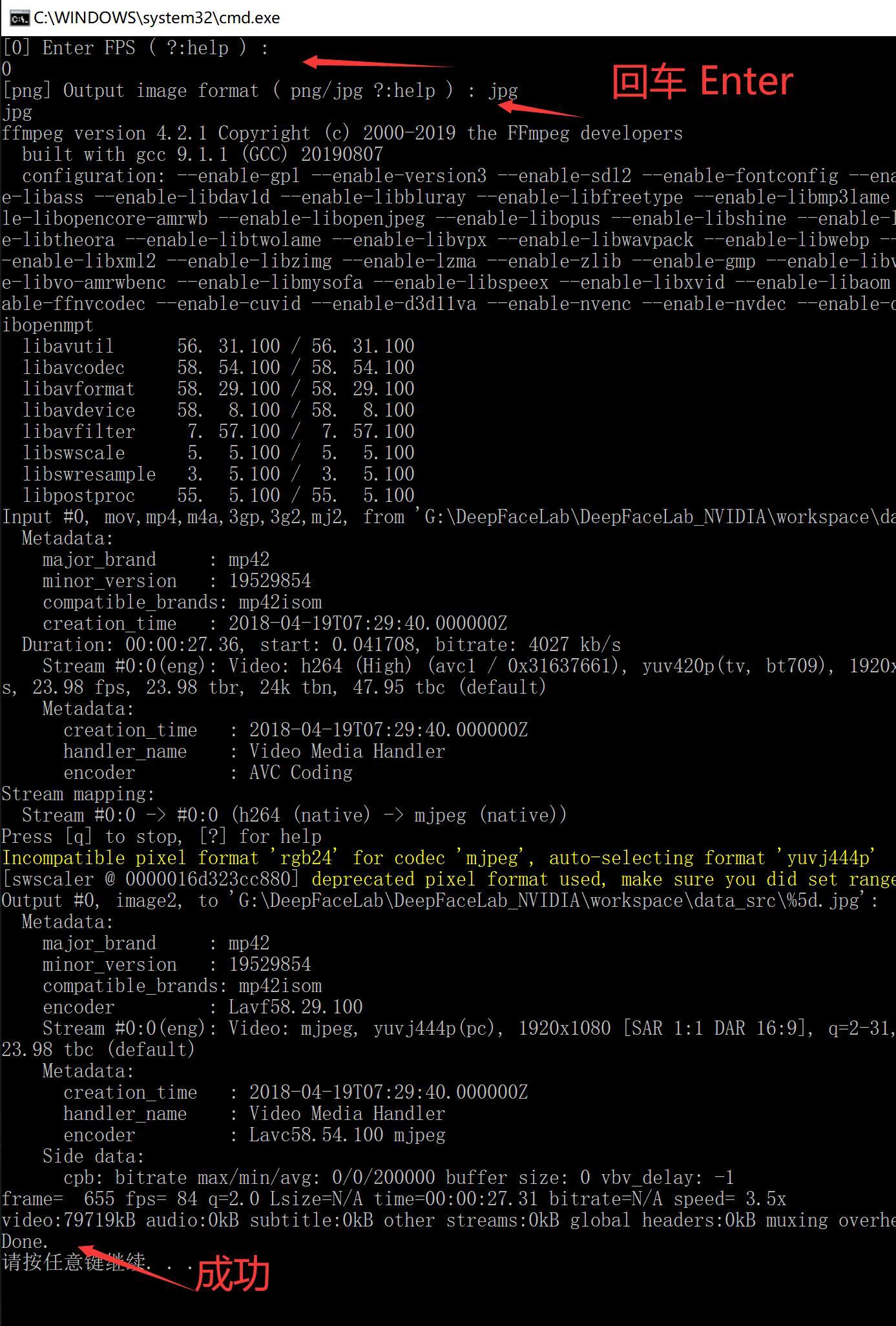
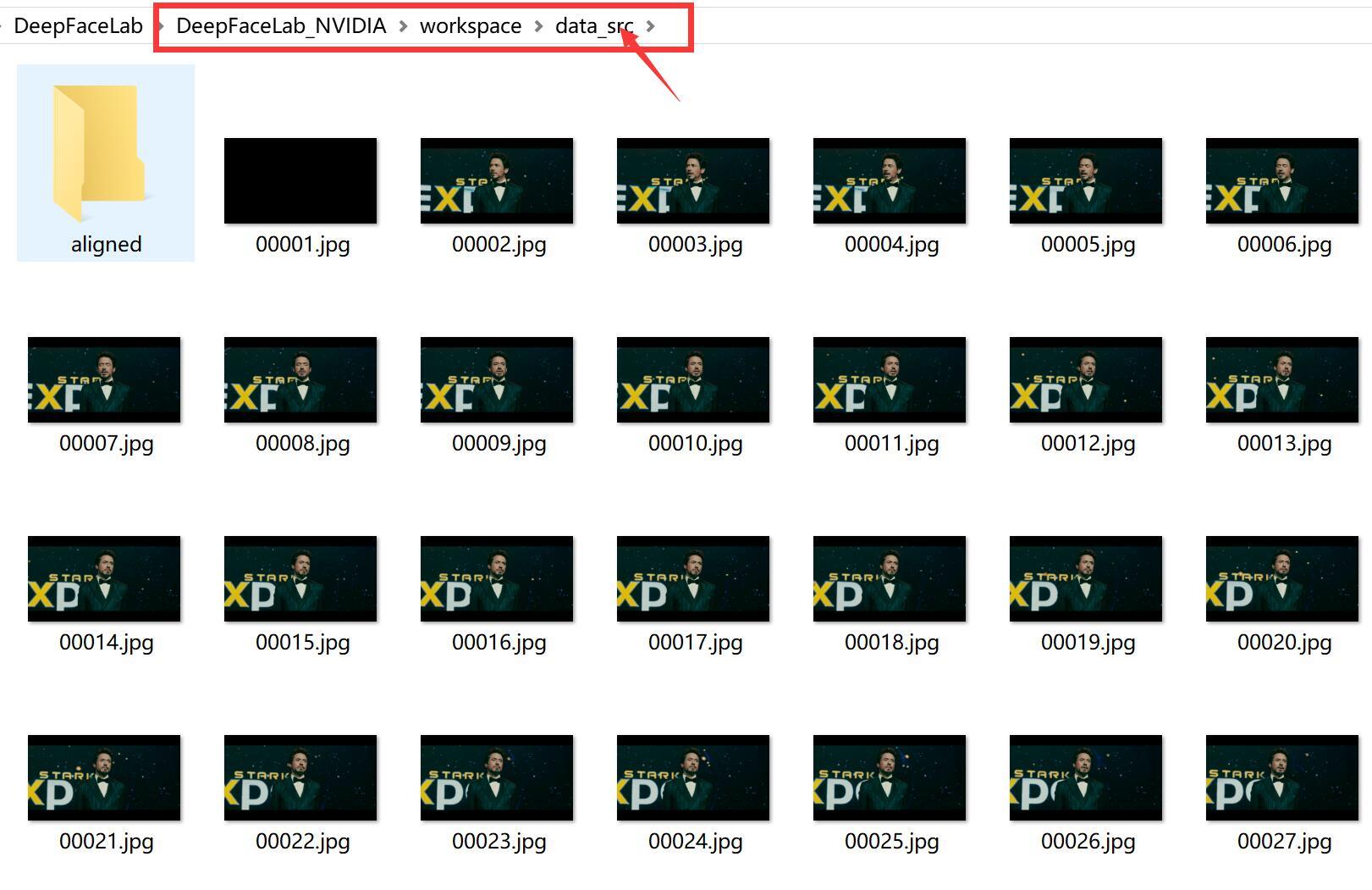
处理完成后,data_src文件夹下面会出现很多图片,这些图片就来自data_src.mp4视频。
3) extract images from video data_dst FULL FPS.bat(把目标视频拆分成图片)
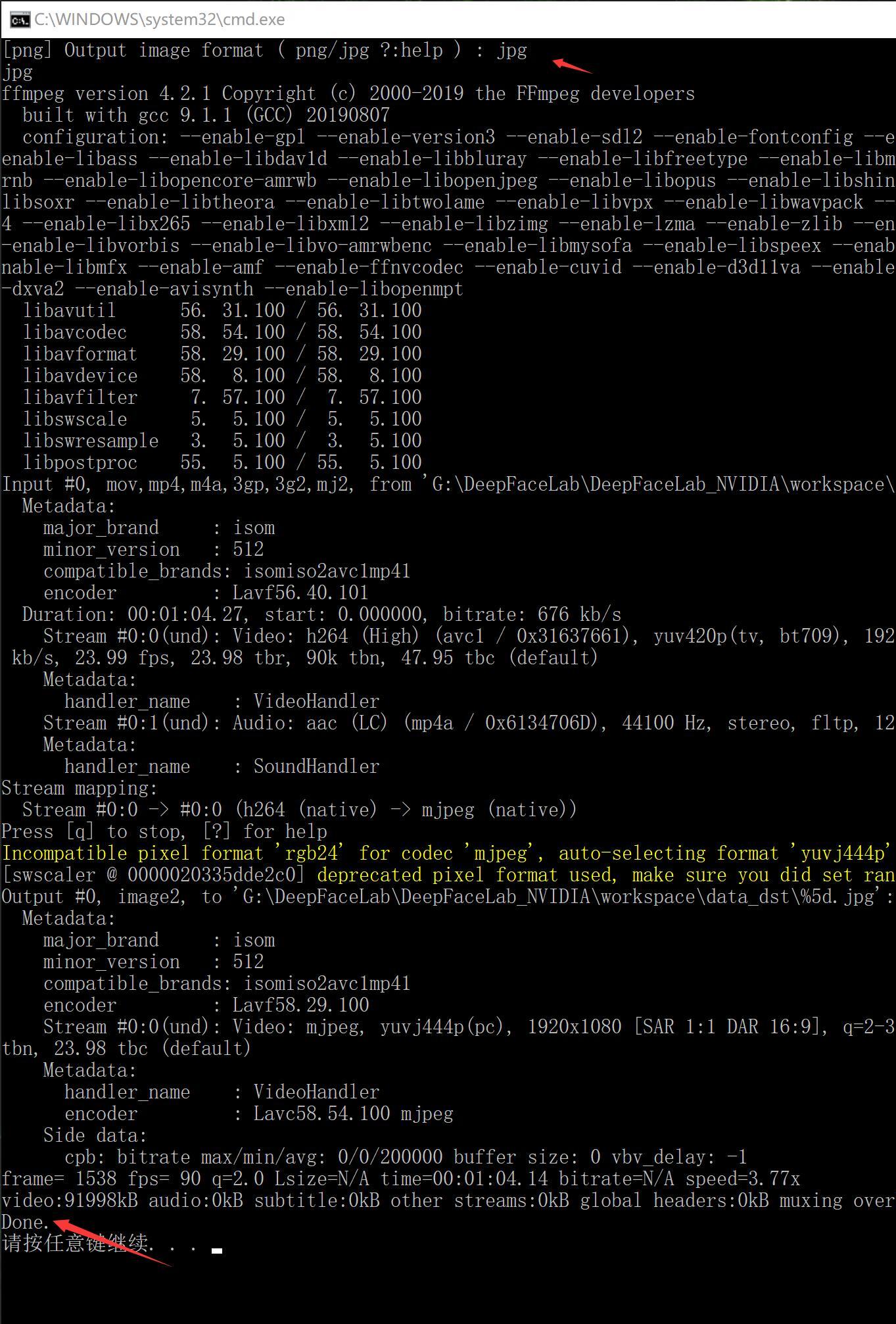
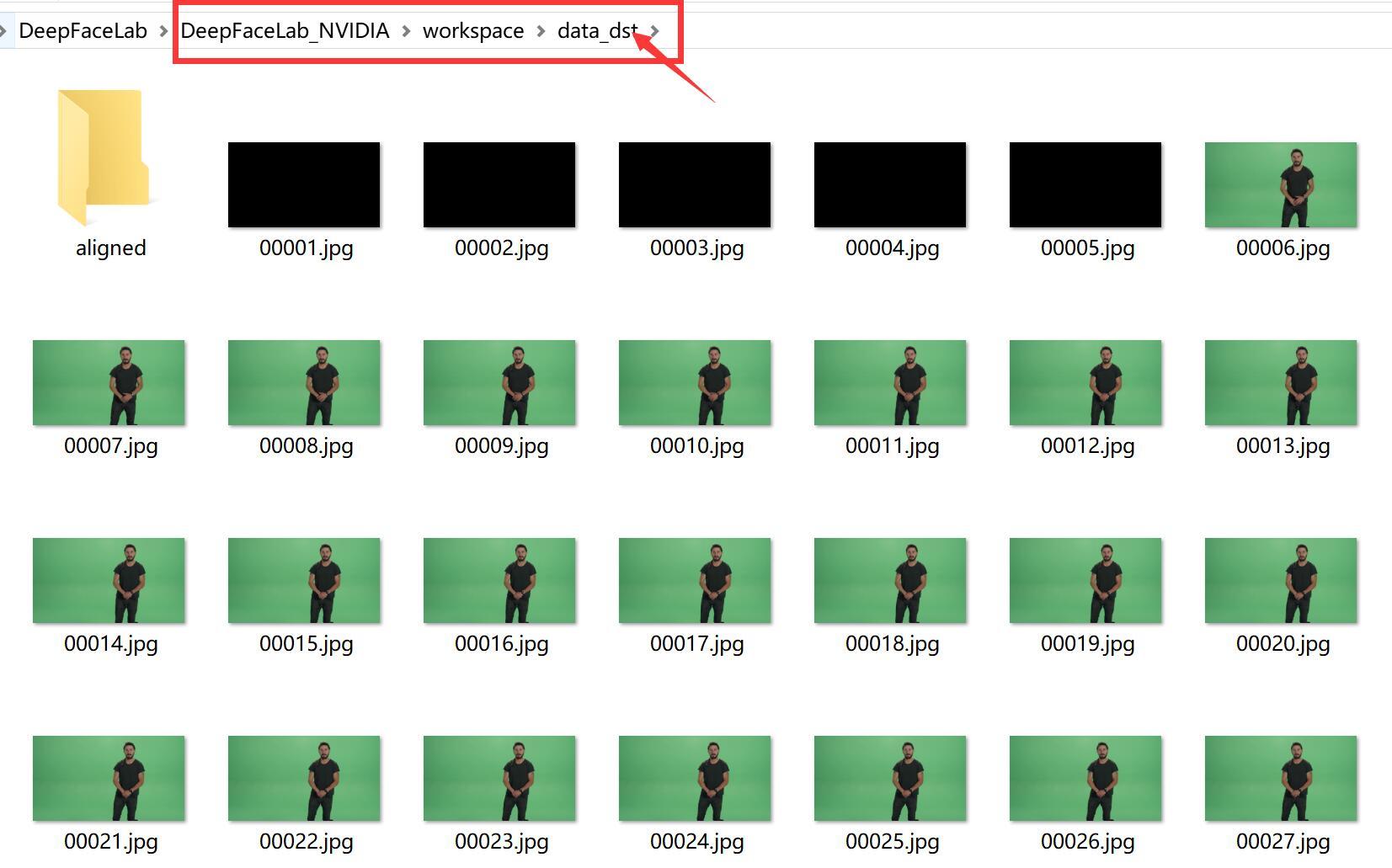
处理完成后,data_dst文件夹下面会出现很多图片,这些图片就来自data_dst.mp4视频。
4) data_src extract faces S3FD.bat(从源图片中提取人脸,也叫切脸)
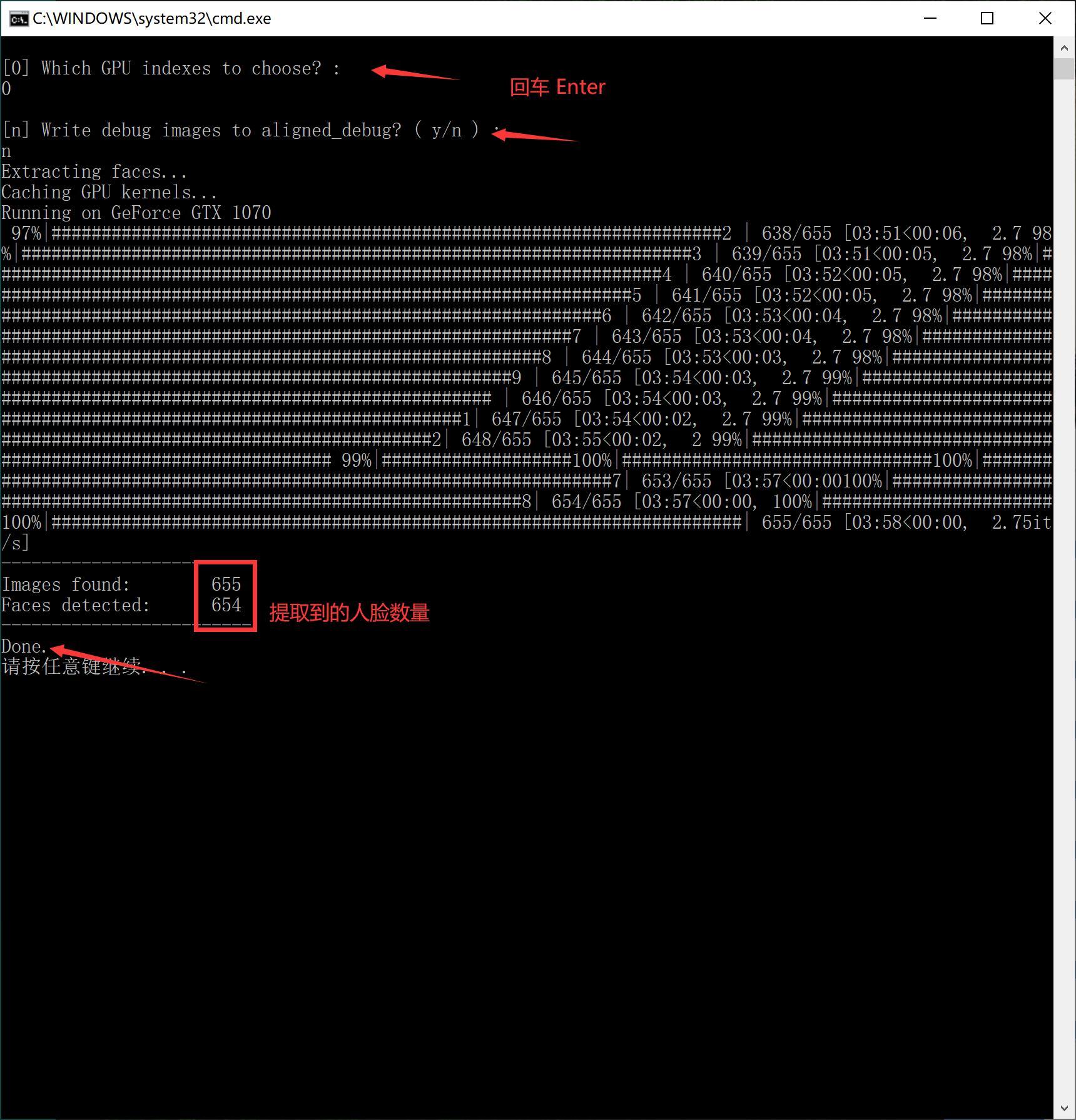

操作成功后,data_src/aligned 文件夹下面会出现唐尼的头像。
5) data_dst extract faces S3FD.bat (从目标图片中提取人脸)
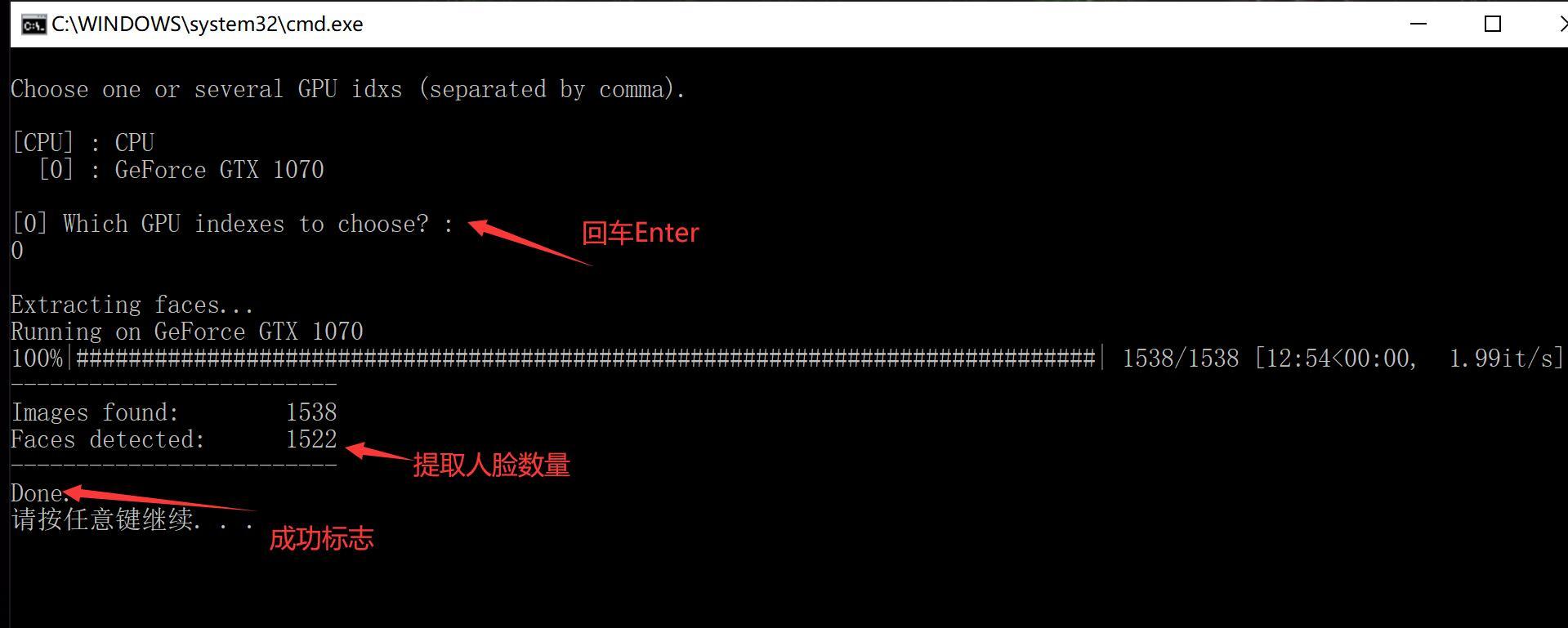
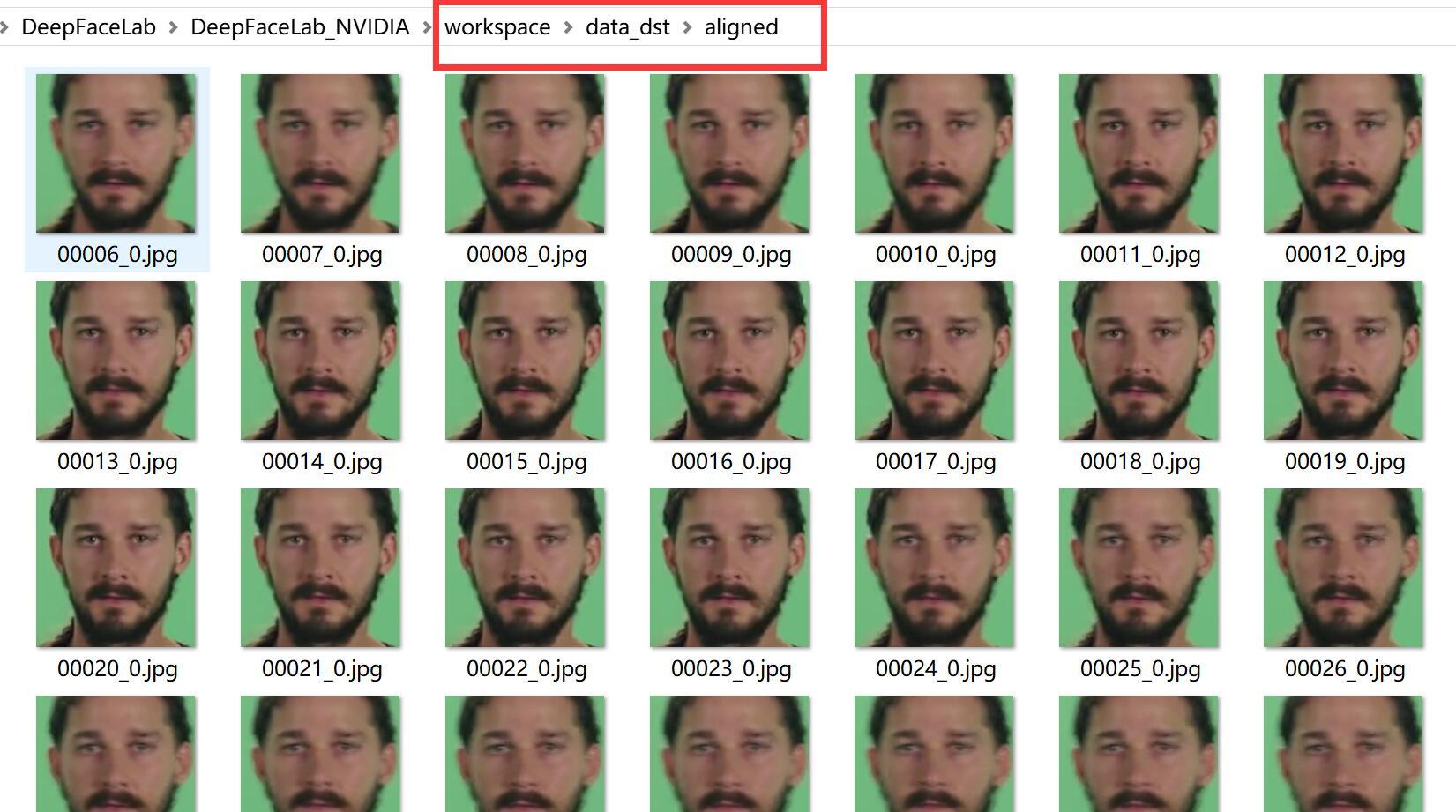

打开里面的图片大概就是这个样子,作为新手看看就好了,不影响你后面的步骤。
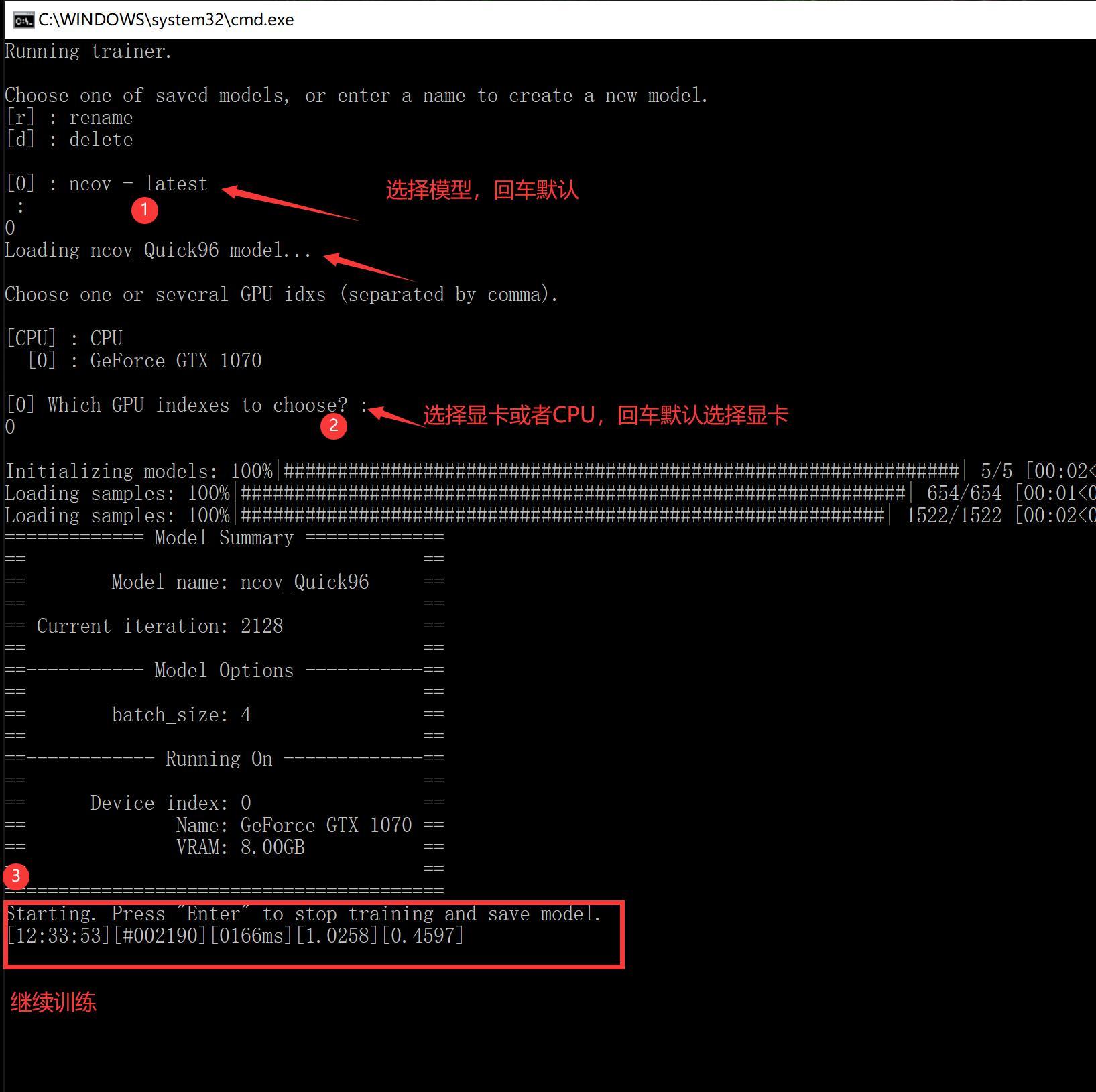
6) train Quick96.bat (训练模型,耗时,不会自己结束)
DeepFaceLab是基于深度学习的软件,而深度学习基本都会涉及到一个叫“模型”的东西。 模型就像是提炼出来的仙丹,可以理解为易容丹。 炼丹自然不是一件简单的事情,而且特别耗时间,还需要好丹炉,好药材。这一部至关重要。
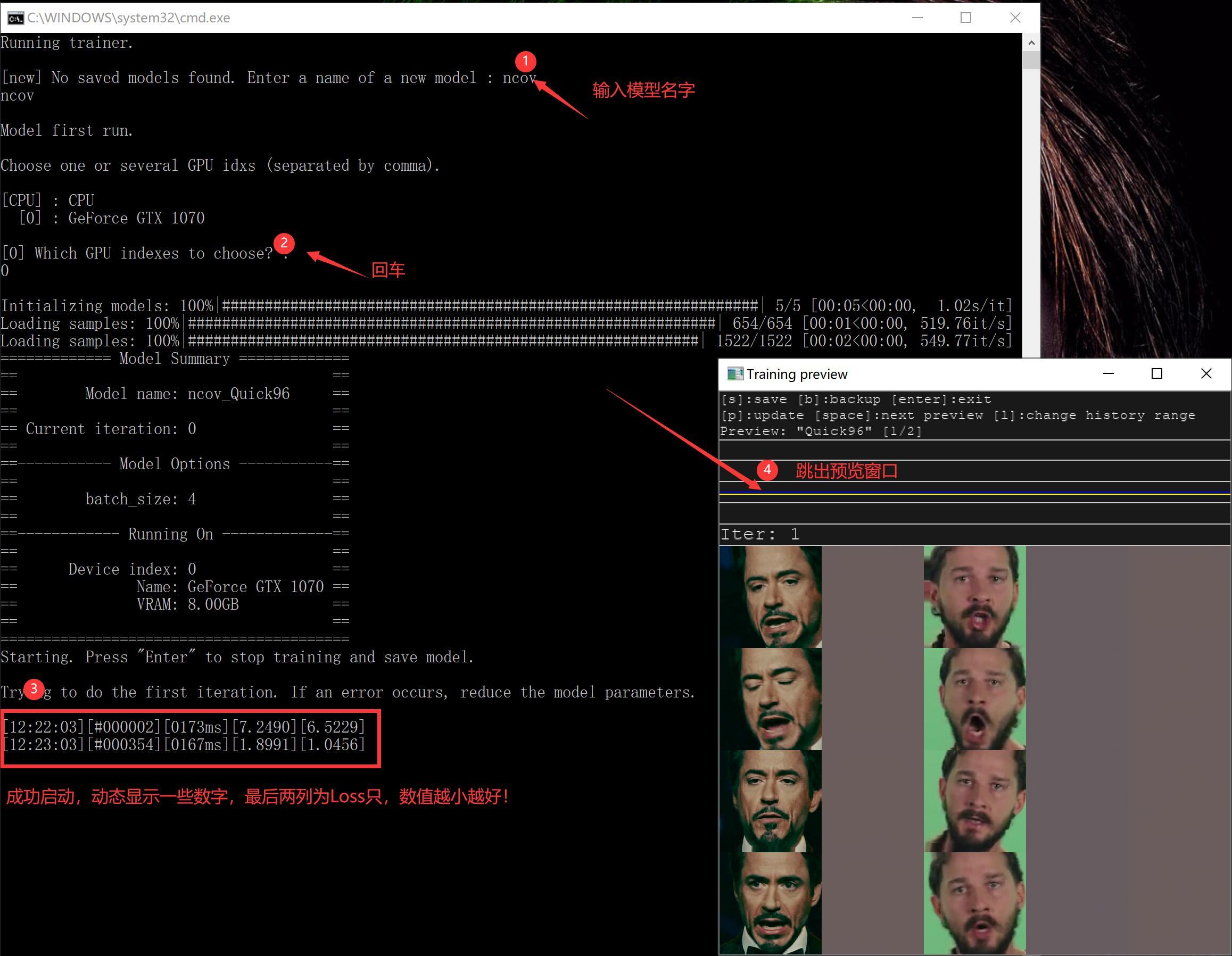
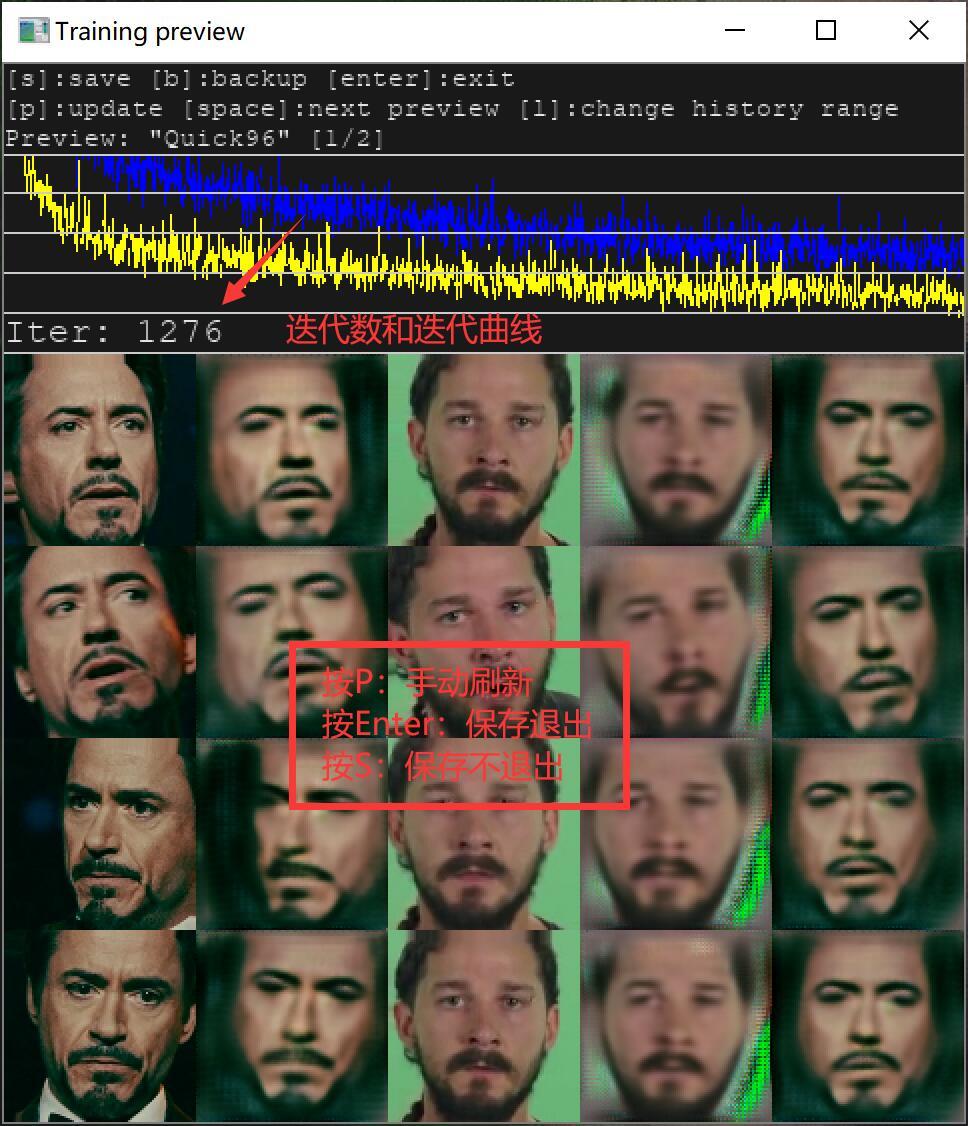
开始训练模型后,还会跳出一个新的窗口预览窗口,上面有使用帮助,迭代历史,迭代次数,还有五列头像。第一列和第二列是源头像,第三列和第四列是目标头像,第五列是最终头像。1,3 是参考标准,2,4,5是生成的头像,生成头像越来越接近参考标准,就证明模型越来越好。
当鼠标点击这个窗口后,在英文输入法下,可以使用快捷键。
P:刷新预览图
S:保存模型
Enter :保存模型,然后退出!
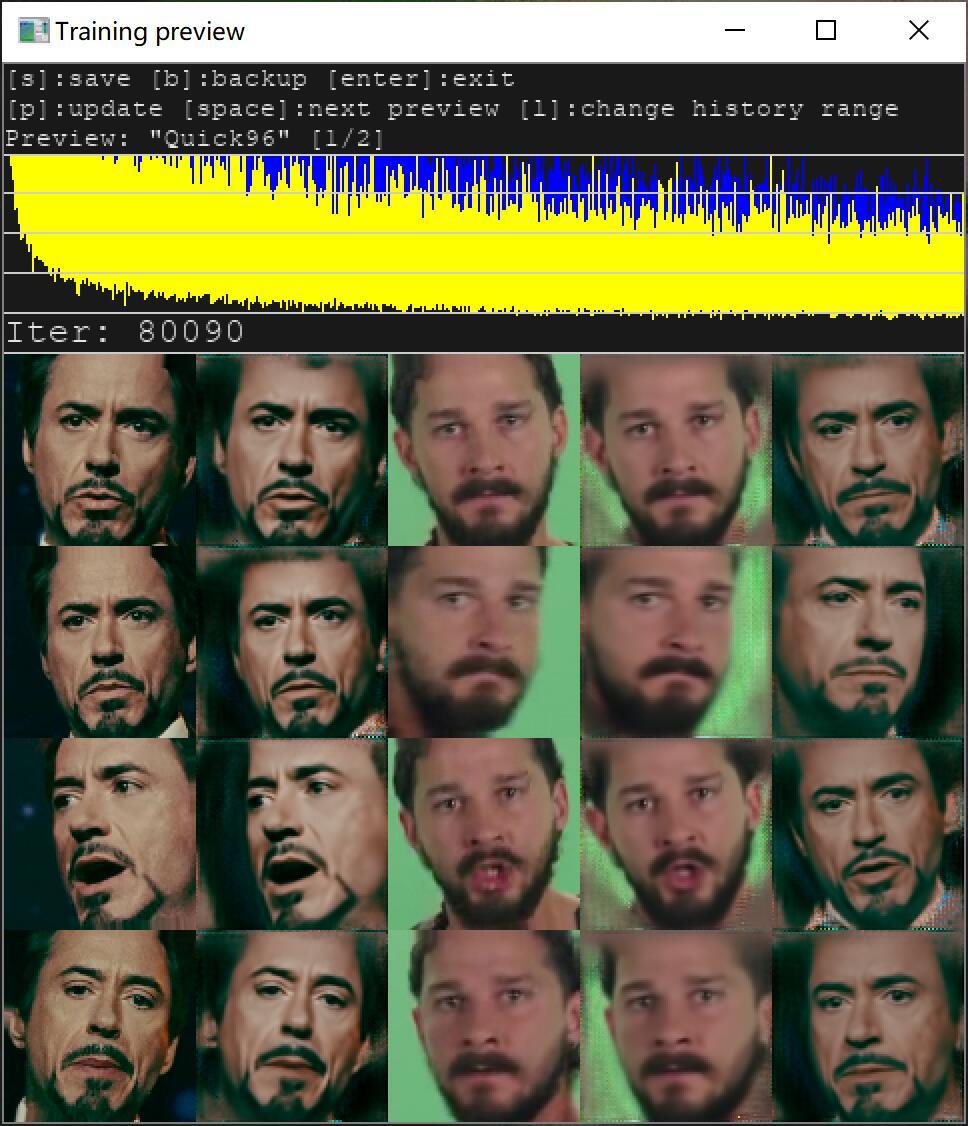
随着时间的推移,2,4,5列头像会越来越清晰,如果你觉得够清晰了,就可以关闭窗口,进入下一个步骤。
7) merge Quick96.bat (图片换脸)

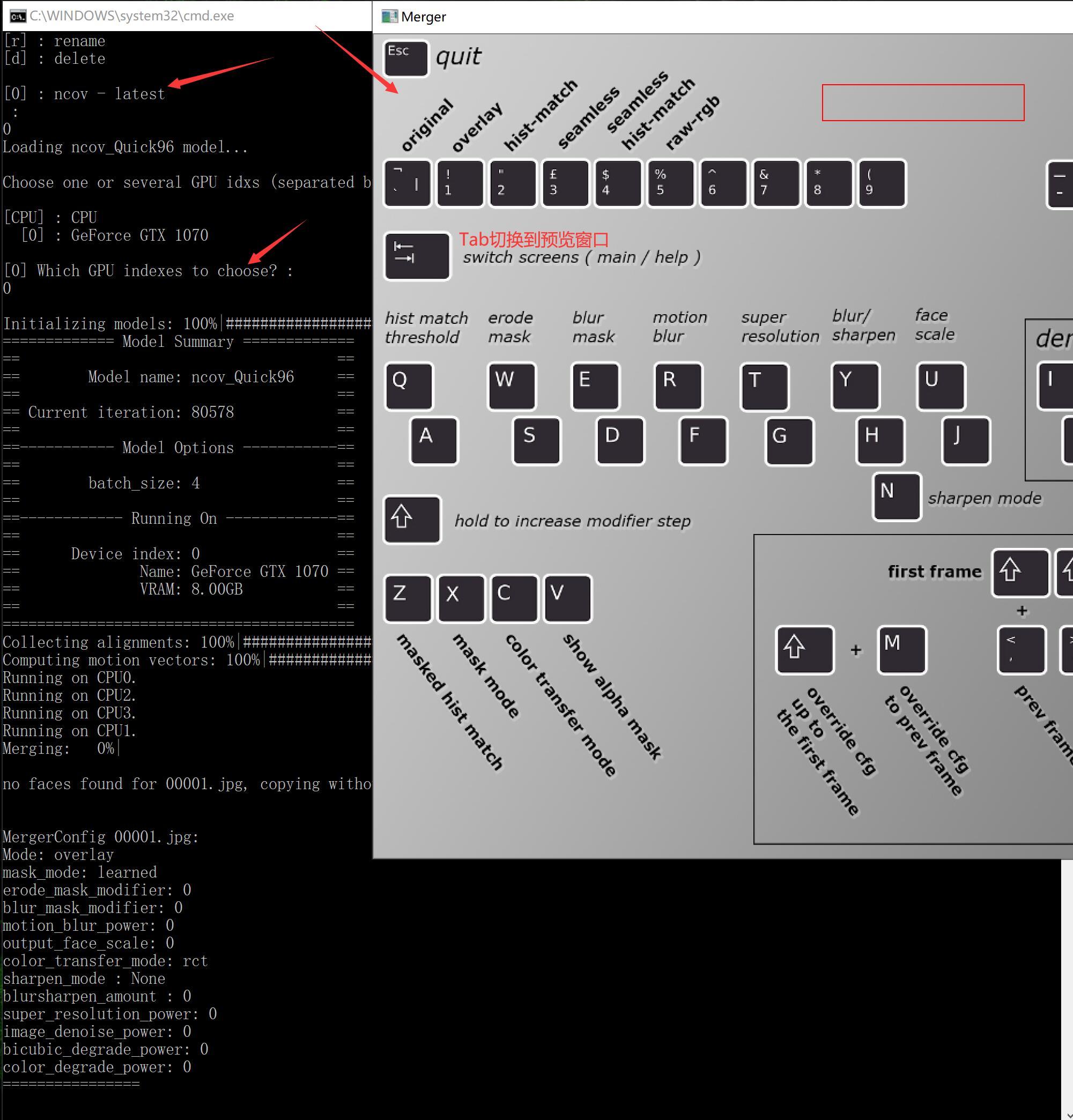

在预览界面上,按对应的快捷键就可以调整效果。调整方法和老版本基本类似。 自动合成的快捷键调整成了shift+>
8) merged to mp4.bat (把图片合成视频)




Yo站长,问个问题啊
train了很多个模型了,但遇到个两难:
一方面每次从头开始train时间太长;另一方面,一个model连续使用很多次了后(我的src一直没变,dst变了大概十来次),特别容易半路崩掉。
所以想问下,能不能直接把model里面的xxx_decoder_src.h5给覆盖到新model里面?试过效果不好,是不是还需要改些什么?
不要一直换!一个好的模型,然后所有模型都在这个基础上跑
感謝老大.辛苦了
Yo站长,问个问题啊
新版本合成的时候出现错误:
main.py merge error :the following arguments are required:–output-mask–dir
这个是什么问题?
好像是却少参数,没有配置–output-mask–dir 这个参数的路径!
train的时候出现错误:
cannot convert float to integer
看看是不是少素材,src和dst的aligned目录
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : GeForce GTX 1060 3GB
[0] Which GPU indexes to choose? :
0
[n] Write debug images to aligned_debug? ( y/n ) :
n
Extracting faces…
Exception: Traceback (most recent call last):
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\joblib\SubprocessorBase.py”, line 62, in _subprocess_run
self.on_initialize(client_dict)
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 66, in on_initialize
nn.initialize (device_config)
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\nn.py”, line 154, in initialize
nn.tf_sess = tf.Session(config=nn.tf_sess_config)
File “D:\Game\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py”, line 1551, in __init__
super(Session, self).__init__(target, graph, config=config)
File “D:\Game\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py”, line 676, in __init__
self._session = tf_session.TF_NewSessionRef(self._graph._c_graph, opts)
tensorflow.python.framework.errors_impl.InternalError: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version
Traceback (most recent call last):
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\main.py”, line 350, in
arguments.func(arguments)
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\main.py”, line 41, in process_extract
force_gpu_idxs = [ int(x) for x in arguments.force_gpu_idxs.split(‘,’) ] if arguments.force_gpu_idxs is not None else None,
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 758, in main
device_config=device_config).run()
File “D:\Game\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\joblib\SubprocessorBase.py”, line 217, in run
raise Exception ( “Unable to start subprocesses.” )
Exception: Unable to start subprocesses.
managed to fix?
discovered the problem?
大佬,在4.2增强阶段,训练完现Copy,然后又Remove删除,最后Done结束,请问是增强成功了还是失败了? 没做什么选择,全部回车。
这样就可以了!
Traceback (most recent call last):
File “C:\Users\timmy\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\main.py”, line 350, in
arguments.func(arguments)
File “C:\Users\timmy\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\main.py”, line 41, in process_extract
force_gpu_idxs = [ int(x) for x in arguments.force_gpu_idxs.split(‘,’) ] if arguments.force_gpu_idxs is not None else None,
File “C:\Users\timmy\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 702, in main
if not cpu_only else nn.DeviceConfig.CPU()
File “C:\Users\timmy\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\nn.py”, line 247, in ask_choose_device_idxs
devices = Devices.getDevices()
File “C:\Users\timmy\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\device.py”, line 144, in getDevices
raise Exception(“nn devices are not initialized. Run initialize_main_env() in main process.”)
Exception: nn devices are not initialized. Run initialize_main_env() in main process.
請按任意鍵繼續 . . .
請問出現了甚麼問題???
managed to fix?
discovered the problem?
您好,我的DeepFaceLab_CUDA里并没有data_src extract faces S3FD.bat文件,只有一个叫4) data_src extract faces MANUAL.bat的文件,打开后它提示Performing 1st pass…
Running on GeForce GTX 1050. Recommended to close all programs using this device.然后就没有动静了
你好 我的版本可能不一樣 到步驟五就不會了
步驟六就 不懂選者那個一個
分別有
6) train AVATAR best GPU/debug.bat/ multi GPU
6) train DF best GPU/debug.bat/ multi GPU
6) train H64 best GPU/debug.bat/ multi GPU
6) train H128 best GPU/debug.bat/ multi GPU
6) train LIAEF128 best GPU/debug.bat/ multi GPU
6) train LIAEF128YAW best GPU/debug.bat/ multi GPU
6) train MIAEF128 best GPU/debug.bat/ multi GPU
你这是1.0版本的。 可以先选h64,把流程跑完!
shift+ > 键就可以全部合成了。
大佬大佬,在换好的视频中,脸部周边边框很明显怎么处理?
2。0版本有很明顯的邊框,閃爍很厲害,顏色怪怪的。調了很多項結果不是很好
+1
有關人物造型的請教….
在來源的dst影片主角的髲型,大約是頭髲半遮的...而src內的人物是全臉的
在截圖時,是如何去截?局部嗎?
又或者在訓練時或合併時有何參數去改變他?
感謝指導!!!!
註:我希望全瞼人物換成有髲型遮蔽的人物後,依然維持髲型遮蔽的狀況.
切换 mask mode
站长站长,我训练模型一开始没有问题,第二次训练时候就开始报错
Error: No training data provided.
Traceback (most recent call last):
File “G:\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Trainer.py”, line 57, in trainerThread
debug=debug,
File “G:\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\ModelBase.py”, line 173, in __init__
self.on_initialize()
File “G:\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\Model_SAEHD\Model.py”, line 763, in on_initialize
generators_count=dst_generators_count )
File “G:\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\samplelib\SampleGeneratorFace.py”, line 46, in __init__
raise ValueError(‘No training data provided.’)
ValueError: No training data provided.
这种怎么解决
没有训练数据!
站长你好,我在图片换脸之后看文件夹merged和原图片一样,并没有换脸,之前的步骤也都没有问题,这是什么原因呢?希望您看到能解答下,谢谢~
我试了个例子,发现后半段没有,我训练了也就是半个多小时,估计是系统没跑完,你是不是训练时间太少了。
站长你好,我在图片换脸后发现merged文件夹里图片还是原来的,并没有换脸,之前训练模型等步骤都没有问题,这是什么原因呢?希望您看到后能解答下,谢谢~
感謝站長的熱心,個人已完成第一個影片,十分開心的,品質也許沒那麼好,但也是個成就,
多謝各位的熱心,及那麼多的教學!
本周,在試第二個影片,是個外景影片,在這要請問一下了
常有鏡頭跟著臉跑的,比如由上而下,在下移的過程,在下巴到胸口的位置,理應如何處理?
在該處,畫面上方只有下巴一部分,其餘均是頸部以下,那不論用手動(會自己跳位置那個),
或自動抓取,好像都抓不到,而作出來的影片,也變成,有閃爍,沒換面,變色,都有..
是須放棄移動鏡頭的那段影片嗎?還是,有其他方法(比如手動截圖,指手動去抓點那樣的)
多謝各位!
是会有这样的情况,脸提取不出来的,目前没办法处理。所以尽量不要用这种dst
多謝您了!
4) data_src extract full_face S3FD
Traceback (most recent call last):
File “C:\Users\Lenovo\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\main.py”, line 349, in
arguments.func(arguments)
File “C:\Users\Lenovo\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\main.py”, line 41, in process_extract
force_gpu_idxs = [ int(x) for x in arguments.force_gpu_idxs.split(‘,’) ] if arguments.force_gpu_idxs is not None else None,
File “C:\Users\Lenovo\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 703, in main
if not cpu_only else nn.DeviceConfig.CPU()
File “C:\Users\Lenovo\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\nn.py”, line 258, in ask_choose_device_idxs
devices = Devices.getDevices()
File “C:\Users\Lenovo\Downloads\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\device.py”, line 144, in getDevices
raise Exception(“nn devices are not initialized. Run initialize_main_env() in main process.”)
Exception: nn devices are not initialized. Run initialize_main_env() in main process.
Pressione qualquer tecla para continuar. . .
希望大大能协助一下,我看入门教程测试了一个例子,但是用默认merge以后视频的脸色不一致而且差的比较多,但是教程上面说请参见deepfake.xyz?没找到,就无耻的在这个帖子下问来了。具体这个颜色问题是能调整么,还是找源视频和目标视频时候的肤色不能差太多啊
为什么我双击8)merged to mp4后,输出完的还是原来的视频?
HELP!!
================= Model Summary =================
== ==
== Model name: new_SAEHD ==
== ==
== Current iteration: 0 ==
== ==
==————— Model Options —————==
== ==
== resolution: 256 ==
== face_type: f ==
== models_opt_on_gpu: True ==
== archi: df ==
== ae_dims: 512 ==
== e_dims: 128 ==
== d_dims: 128 ==
== d_mask_dims: 128 ==
== masked_training: True ==
== learn_mask: True ==
== eyes_prio: False ==
== lr_dropout: False ==
== random_warp: True ==
== gan_power: 0.0 ==
== true_face_power: 0.001 ==
== face_style_power: 0.0 ==
== bg_style_power: 0.0 ==
== ct_mode: none ==
== clipgrad: False ==
== pretrain: False ==
== autobackup_hour: 0 ==
== write_preview_history: False ==
== target_iter: 0 ==
== random_flip: True ==
== batch_size: 8 ==
== ==
==—————- Running On —————–==
== ==
== Device index: 0 ==
== Name: Tesla P100-PCIE-16GB ==
== VRAM: 15.92GB ==
== ==
=================================================
Starting. Press “Enter” to stop training and save model.
Trying to do the first iteration. If an error occurs, reduce the model parameters.
Error: OOM when allocating tensor with shape[8,256,256,256] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node DepthToSpace_11 (defined at D:\ing\_internal\DeepFaceLab\core\leras\tensor_ops.py:303) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[node concat (defined at D:\ing\_internal\DeepFaceLab\models\Model_SAEHD\Model.py:423) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
7) merge Quick96.bat
done 之后还能修改merge merge 的图吗
根本假到一个恶心,参照 deepfaker.xyz 不能用个链结或文章标题吗
32位操作系统可以使用吗?
(⊙o⊙)…现在还有32位系统?因为底层的一些包都是根据位数来编译的,所以32位应该不行。
哦,谢谢
站长你好!请问一下我用“train Quick96” 跑到“Initializing models: 100%”之后一直不见出现有您在文章中所说“③中的一行一行跳动的数字”的情况,就一直在“Initializing models: 100%”不动,请问这是卡住了还是它一直在训练中?
改编一下黑色窗口的大小,据说有用!
站长好,我训练后的结果,人物面部出现一闪一闪的情况(一会是src,一会是dst),是什么原因呀?
那是因为你删除了data_dst/aligned下面的头像。
我想问一下,我训练出的模型,能不能够复用呢,用在其他的替换上?
可以,但是搞不好的话,可能会四不像!
你好,我想问下使用其他人分享的模型时候,是怎么设置?model文件夹下只有一个模型需不需要设置,如果有两个模型需要怎么设置
就是把模型文件放到自己的model 目录就好啦!
请问7)第七步没有出现交互式窗口是怎么回事呢?
有什么提示么?
大佬好,我遇见了一个问题,实在搞不定了,麻烦给帮忙看下吧。GPU、nivida驱动、CUDA都装了,但是train都时候,一直提示下面都错误。
tensorflow/stream_executor/cuda/cuda_driver.cc:300] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
好像检车不到设备。 你的显卡是N卡么?
站长你好,第一次在训练模型时,loss值在0. 15左右就基本不变了,请问是否和原视频的清晰度有关(src那个视频很糊),还是其它什么问题
请问,在dst的角色脸上,加上类似动作捕捉的跟踪点。(就是在脸上画不同地方画上黑色的标记点)。对脸的角度识别、最后的合成效果有帮助吗?
站长您好。请问在dst视频拍摄前期加上动捕常用的标记点(在脸上画一些黑色小点)。会对我们的训练和最终效果有帮助或者提高吗?
这个对DFL没用的。
哦,了解了。多谢站长。另外,我测试的成果。一直带着胡子。请问站长。这个胡子怎么调没呀。原视频没有胡子。目标修改视频(dst)里有胡子。能把胡子去掉吗?
这是啥情况,没反应了
No node-device colocations were active during op ‘encoder/down1/downs_0/conv1/weight/Initializer/_cai_’ creation.
Device assignments active during op ‘encoder/down1/downs_0/conv1/weight/Initializer/_cai_’ creation:
with tf.device(None):
with tf.device(/GPU:0):
按回车也没反应
Initializing models: 0%| | 0/5 [00:00<?, ?it/s]
Error: Cannot assign a device for operation encoder/down1/downs_0/conv1/weight/Initializer/_cai_: Could not satisfy explicit device specification '' because the node node encoder/down1/downs_0/conv1/weight/Initializer/_cai_ (defined at D:\Deepfacelab\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\initializers\__init__.py:13) having device Device assignments active during op 'encoder/down1/downs_0/conv1/weight/Initializer/_cai_' creation:
with tf.device(None):
with tf.device(/GPU:0): was colocated with a group of nodes that required incompatible device ‘/device:GPU:0’
Colocation Debug Info:
Colocation group had the following types and devices:
Assign: CPU
Const: CPU
Fill: CPU
VariableV2: CPU
Identity: CPU
Colocation members and user-requested devices:
encoder/down1/downs_0/conv1/weight/Initializer/_cai_/shape_as_tensor (Const)
encoder/down1/downs_0/conv1/weight/Initializer/_cai_/Const (Const)
encoder/down1/downs_0/conv1/weight/Initializer/_cai_ (Fill)
encoder/down1/downs_0/conv1/weight (VariableV2) /device:GPU:0
encoder/down1/downs_0/conv1/weight/Assign (Assign) /device:GPU:0
encoder/down1/downs_0/conv1/weight/read (Identity) /device:GPU:0
Assign_1 (Assign) /device:GPU:0
Assign_172 (Assign) /device:GPU:0
出错了 好像是调用不到设备。考虑下显卡型号和驱动的问题。