DeepFaceLab3:视频换脸完整流程
对于刚入门的朋友来说,你给他直接上心法肯定没啥有,最直接的还是教招式。实操,才有感觉嘛!DeepFaceLab虽然版本一直在升级,但是整体步骤和执行逻辑并没有太大变化。所以老教程现在一样能用了。但是为了教程的完整性,我就全部重写一遍,稍作改进。
安装软件
安装过程其实非常简单。一般发布的软件包都是.exe结尾,本质上其实就是一个用7z压缩的压缩包而已。所以安装只要双击就好了,大家都会的!
安装的时候需要注意几个点。
第一:杀毒软件可能会有木马警报,添加信任就好。杀毒软件可能会无警报删文件,导致执行的时候出现未知错误。这种情况可以先退杀毒软件,安装完了就不受影响。
第二:安装的时候记得选好路径
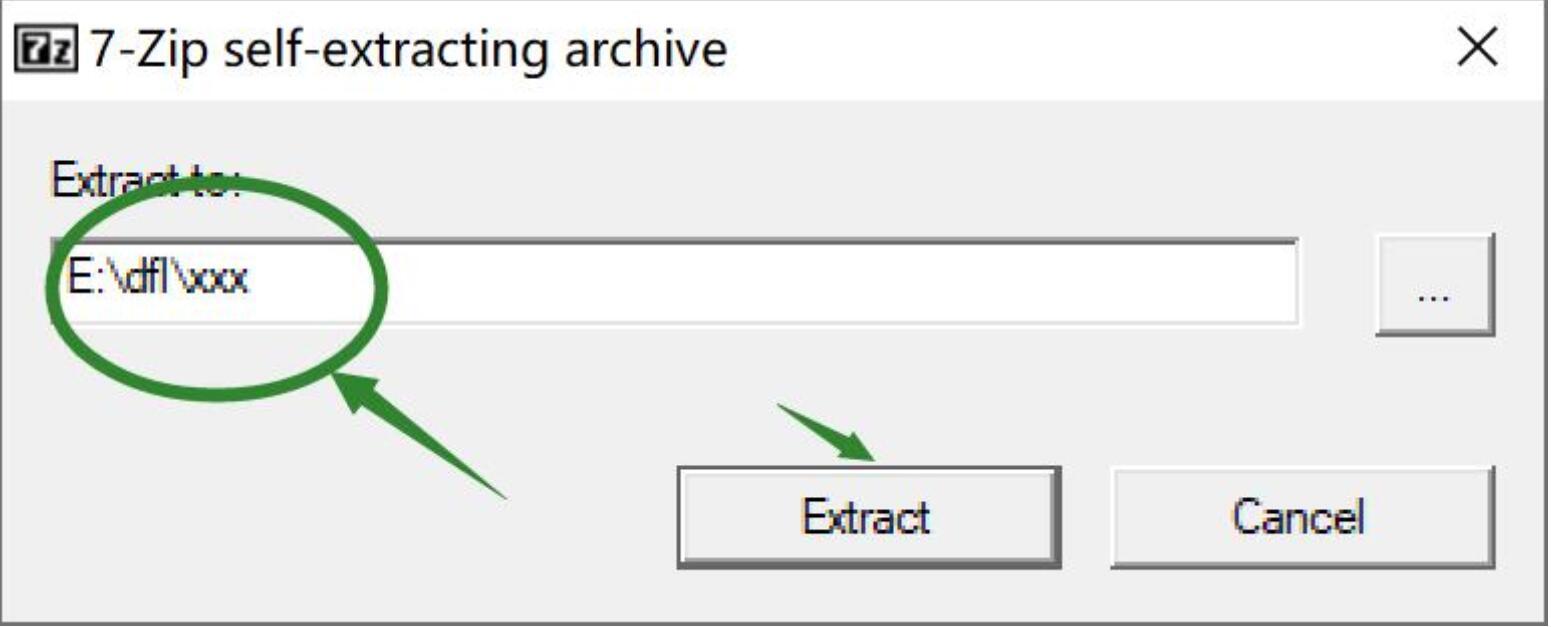
路径并没有硬性要求,默认是解压到安装包所在路径。有不少人对路径并不是很敏感。比如通过QQ群文件下载的,就直接解压在路径超深的QQ缓存目录中,这样可能会出问题,而且不好找。最好是放在C盘外的其他盘的根目录。文件路径不强制英文,但是依旧不推荐中文。文件名不要用特殊字符,降低出错概率。
第三:
输入密码

我发布的文件如果有密码,就都是deepfaker.xyz。不管哪个版本直接输入就好了。当然,你任性,也可以不输入。
不输入就是上面这种结果。然后你点1,2,3,4每个步骤都点不动。因为不看英文或者大意,犯这个错误的也不少。

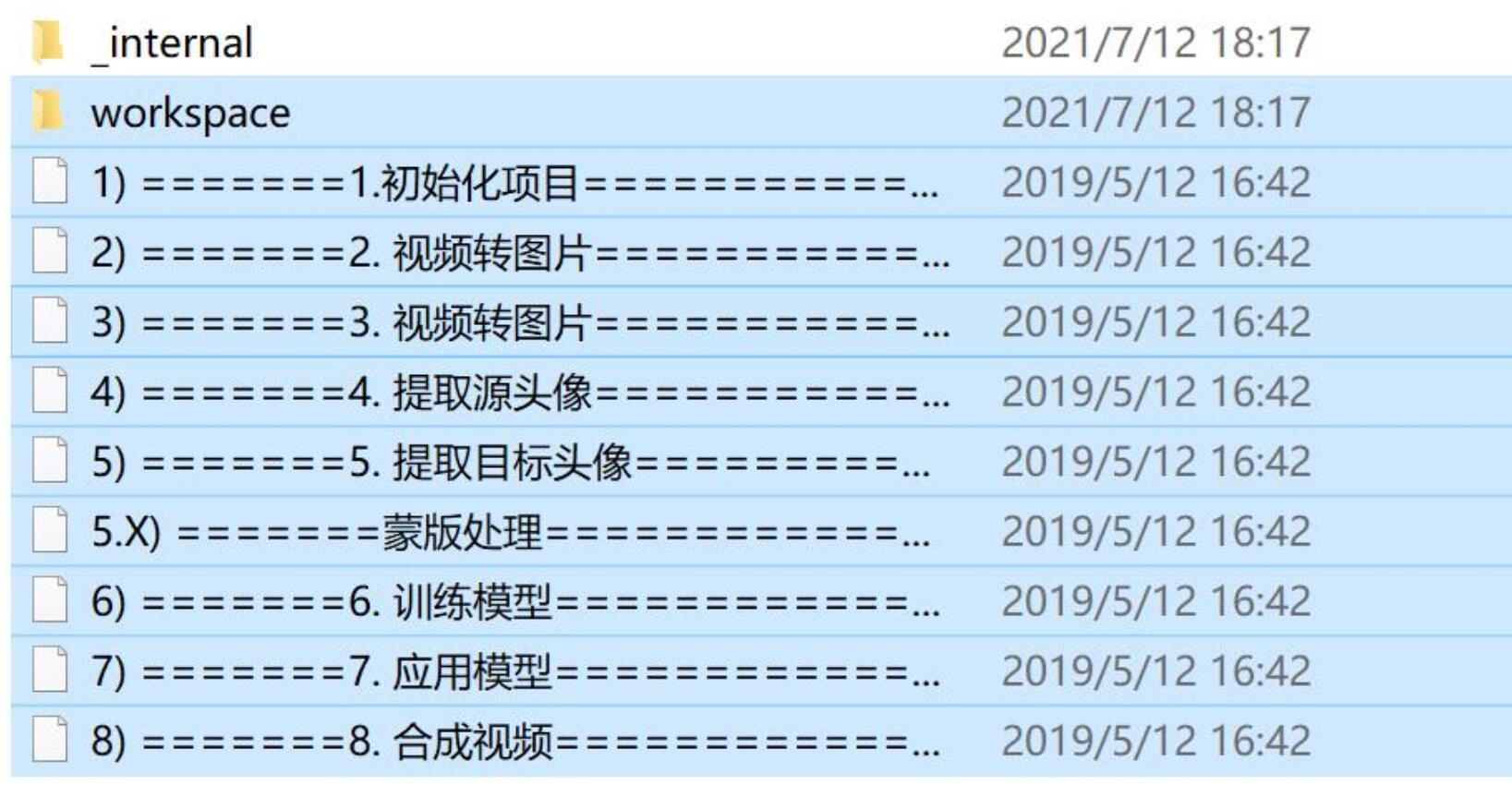
正确的打开方式是这样的。里面会有_internal和workplace文件夹。前者放的是源代码和软件相关的内容,后者是工作目录,上一篇有讲过。除此之外还有一堆.bat结尾的文件。可以把这些称为脚本或者批处理文件。里面是一行行的DOS命令。
批处理文件打开方式和EXE一模一样,Double kill ~~Double click 双击打开!每一个批处理文件都干一件事情,我们要做的就是按一定的顺序点击这些文件,就能完成换脸。是不是挺简单?
执行步骤
DFL换脸的思路是,想将视频转换成图,从图片中提取人脸,从人脸中学习特征。然后应用模型,先对图片进行换脸,然后把图片合成视频,同时带上原视频的音轨。
具体来说可以分为如下几步:
- 源视频转图片
- 目标视频转图片
- 提取源头像
- 提取目标头像
- 训练模型
- 应用模型
- 合成视频
批处理文件步骤如下:
- 源视频转图片 extract images from video data_src.bat
- 目标视频转图片 extract images from video data_dst FULL FPS.bat
- 提取源头像 data_src faceset extract.bat
- 目标头像提取 data_dst faceset extract.bat
- 训练轻量级模型 train Quick96.bat/SAE/AMP
- 应用轻量级模型 merge Quick96.bat /SAE/AMP
- 合成 MP4 视频 merged to mp4.bat
杂七杂八交代清楚了就可以开始操作,本文会将每一个步骤截图说明。但是为了控制文章的体型,以操作为主。一些常见错误或者参数详解,会在后续文章中完成。关于操作,这里做一个重点提示:遇事不决按回车!
Step1:源视频转图片
双击批处理文件源视频转图片 extract images from video data_src.bat
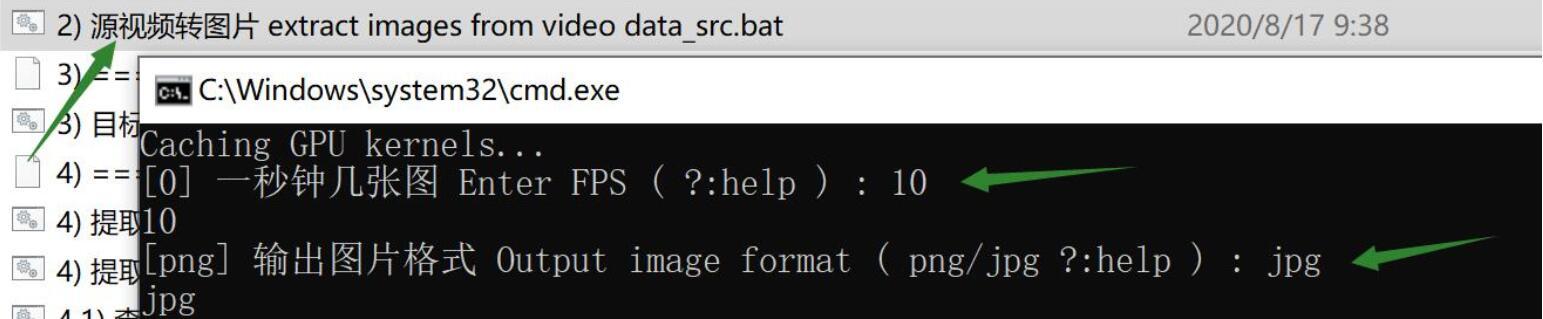
跳出黑色窗口,输入10回车,然后输入jpg回车,就会自动开始将视频分解为图片。
FPS:视频有一个指标叫帧率,常见有24,30,60等,代表一秒钟有几张。第一个参数输入10指的是一秒钟只取10张;不输入直接回车,默认帧率是30就取30张。因为很多影视剧画面相对固定,没必要全部取,否则后面会浪费大量提取时间,而且模型训练压力也会加大。
Format: 图片格式,主要是jpg和png。png是无损格式,但是JPG能在保证画质的情况下减少巨量的空间。所以如果不是要求特别变态,一般都用jpg。这样可以减少空间,节省时间
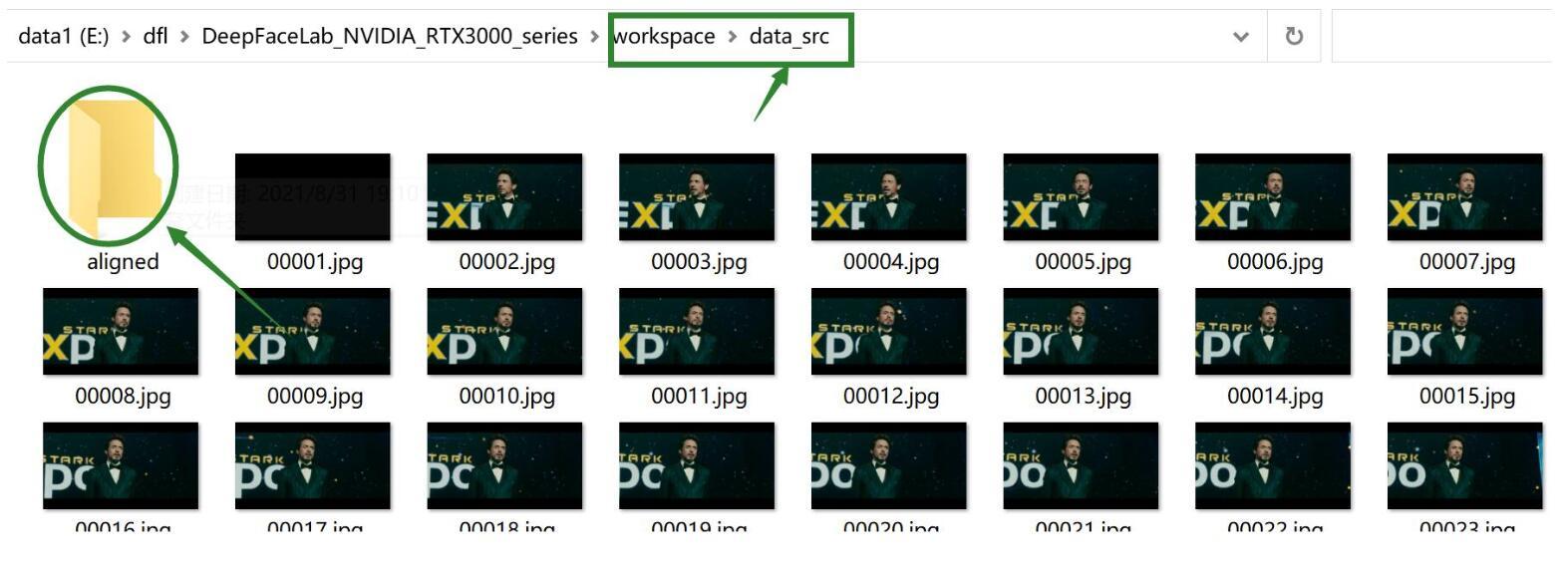
正常情况下,这个步骤执行非常快,出现“搞定/done” 的字样就是执行完成了。完成后,workplace/data_src下面就会出现很多图片,这就是从视频里分解出来的图片。文件名一般为0000x.jpg,其实这里面命名可以随意,没有强制要求。这里还有一个aligned的文件夹,是为后面步骤准备的。
Step2:目标视频转图片
双击批处理文件目标视频转图片 extract images from video data_dst FULL FPS.bat
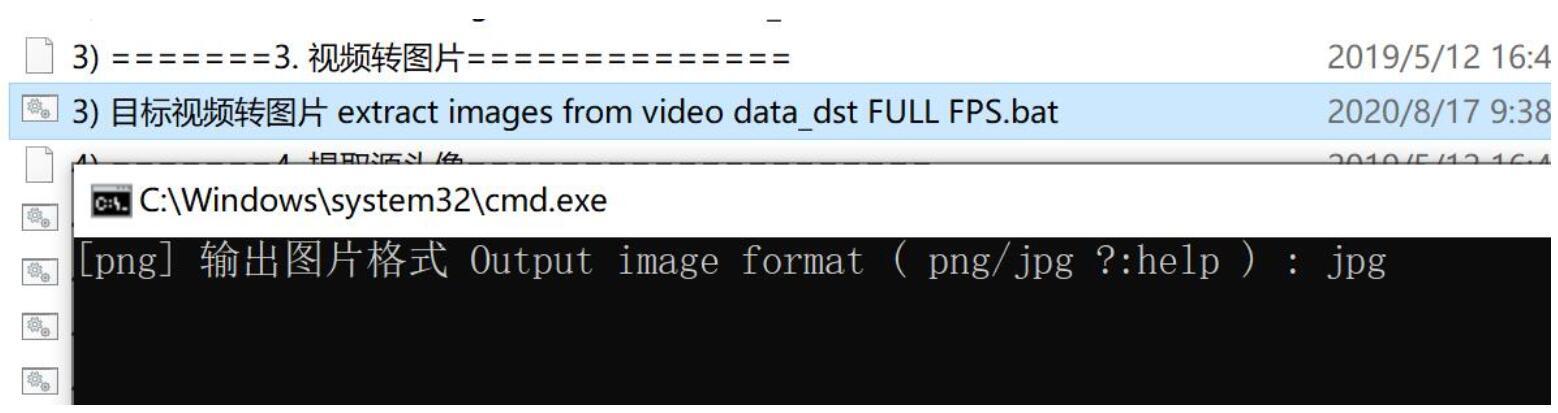
和上面的步骤类似,这次处理的是dst视频。因为dst必须一帧不落,所以没有FPS选项,只有图片格式这一个选项。
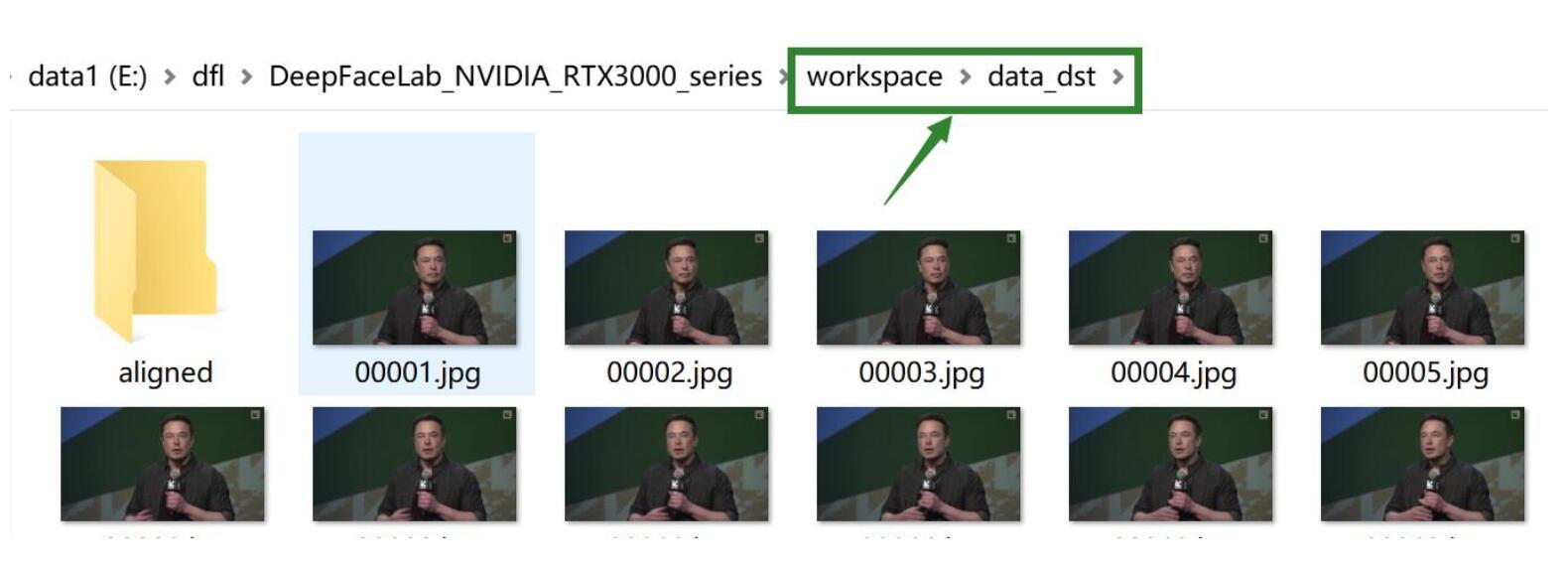
处理完后的图片保存在workspace/data_dst里面。
Step3:提取源头像
双击批处理文件提取源头像 data_src faceset extract.bat
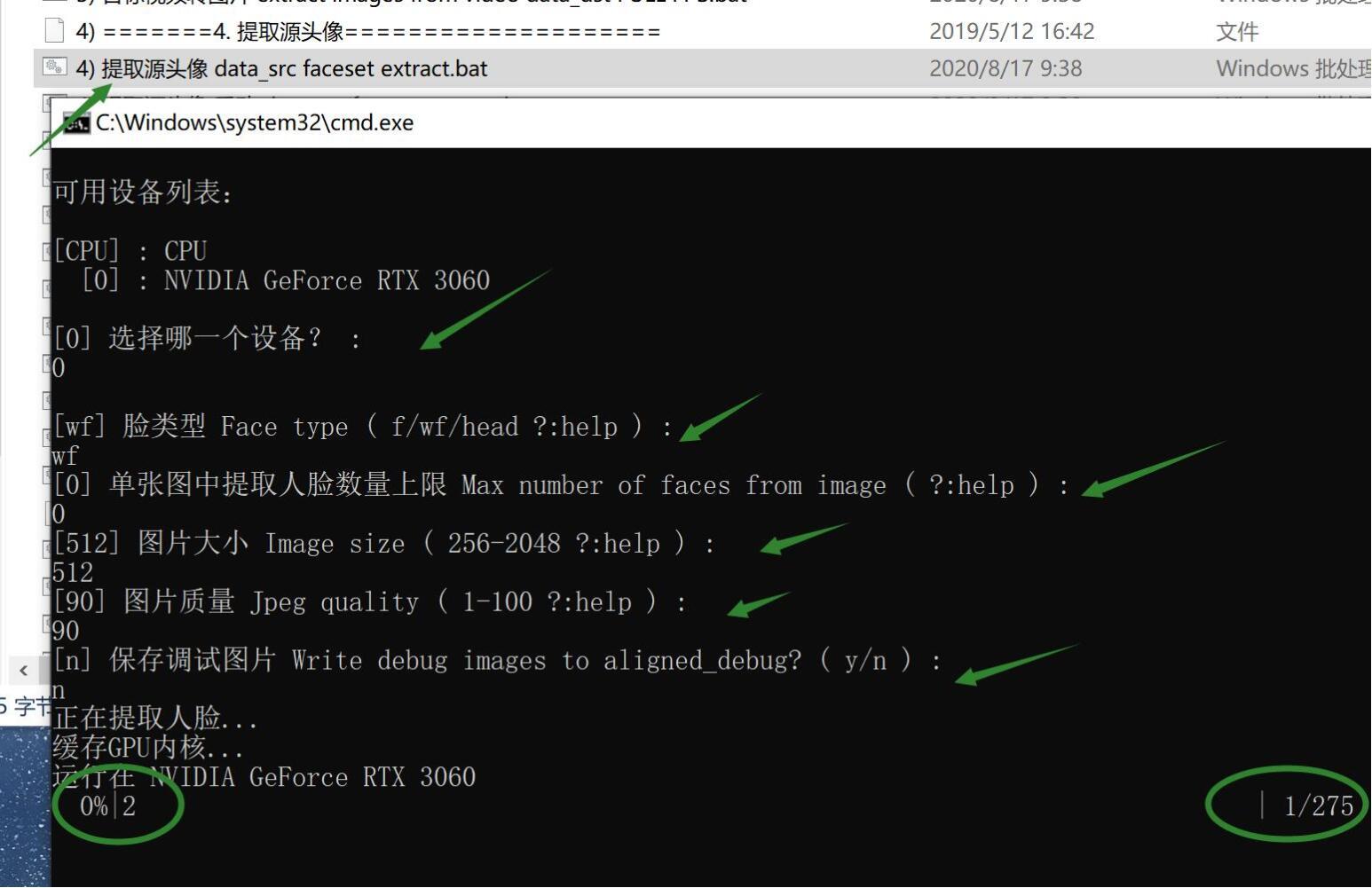
这一步的作用是提取源素材图片中的人脸。这里有六个参数,一般只需一路回车即可。第一次使用需要缓存GPU内核,需要稍微等一等。开始提取后底部有显示进度,当进度到100%,会显示图片数量和提取到的人脸数量,并出现“搞定!!!” 就证明已经出来成功并且处理完成。
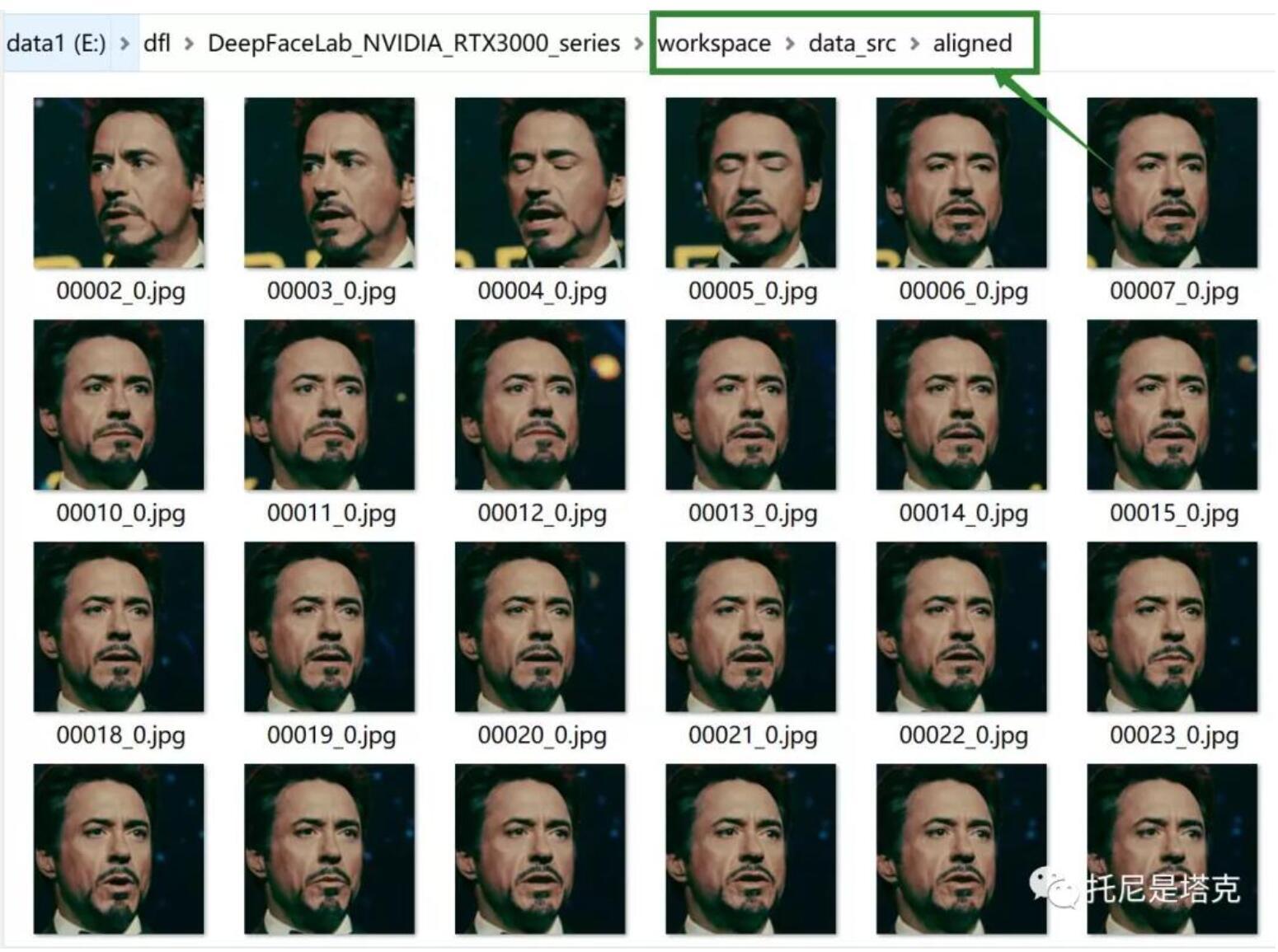
处理完成后,头像保存在data_src/aligned下面。
不少人在这个环节会遇到问题。
常见问题是:
- 驱动不够新,去官网下载更新到最新版本即可。
- 软件不够新,deepfaker.xyz 上获取新版
- 显卡软件不匹配, A卡用Directx12,不要用rtx3000版。
提取完之后,如果src素材比较复杂,就需要做一些筛选。这个筛选可以写一篇很长的文章。这里简要说一下。主要是把一些不需要的素材删除:
- 很模糊的可以直接删除
- 不是目标人物的可以直接删除
- 图片残缺的删除
- 脸部有遮挡的删除
- 脸部光照差异特别大的删除
- …..
Step4:提取目标头像
双击批处理文件目标头像提取 data_dst faceset extract.bat
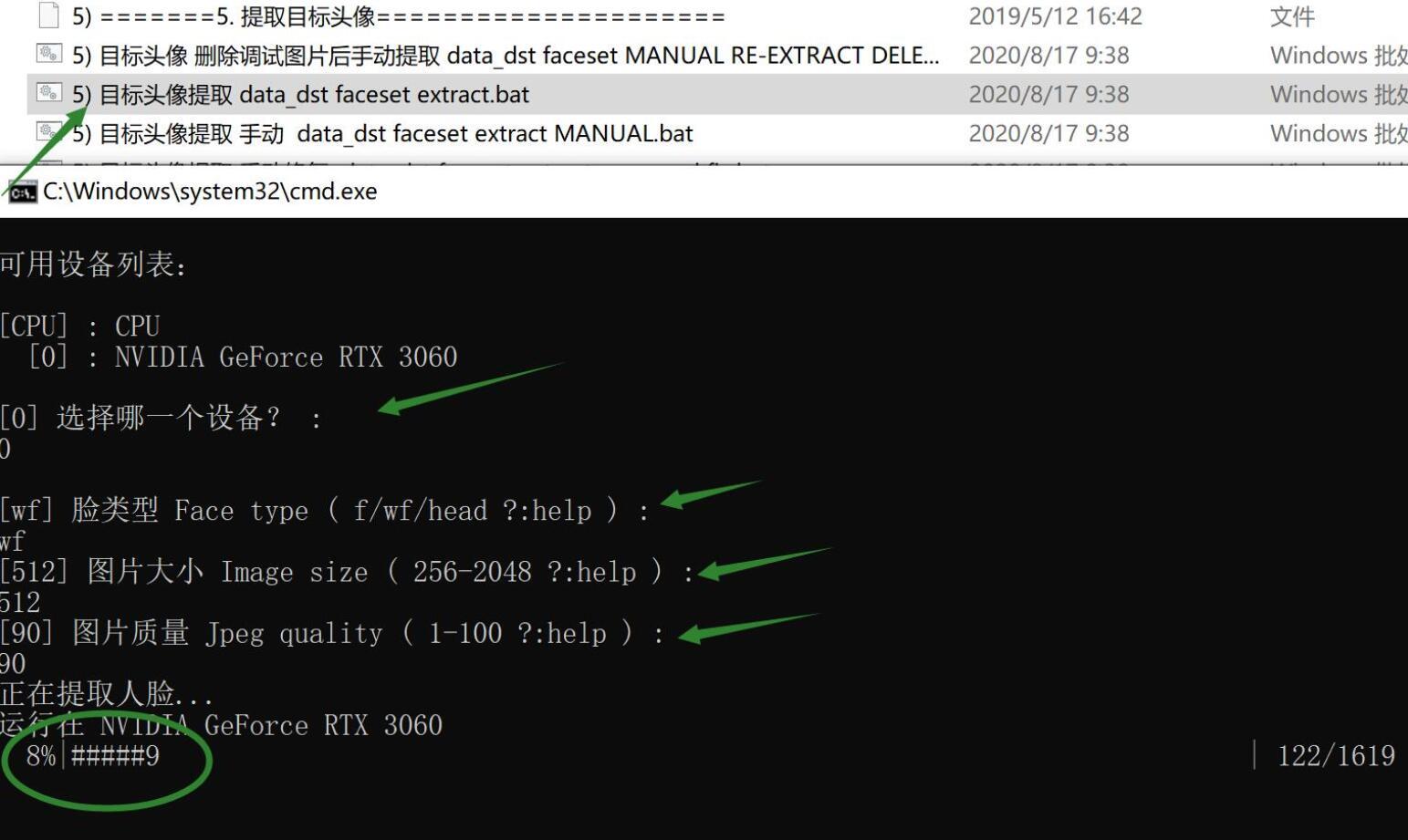
这一步的作用是提取目标素材图片中的人脸。和上一步非常类似,这里就是少了一个“保存调试图片”的参数。其实也不是少了,而是默认就执行了。
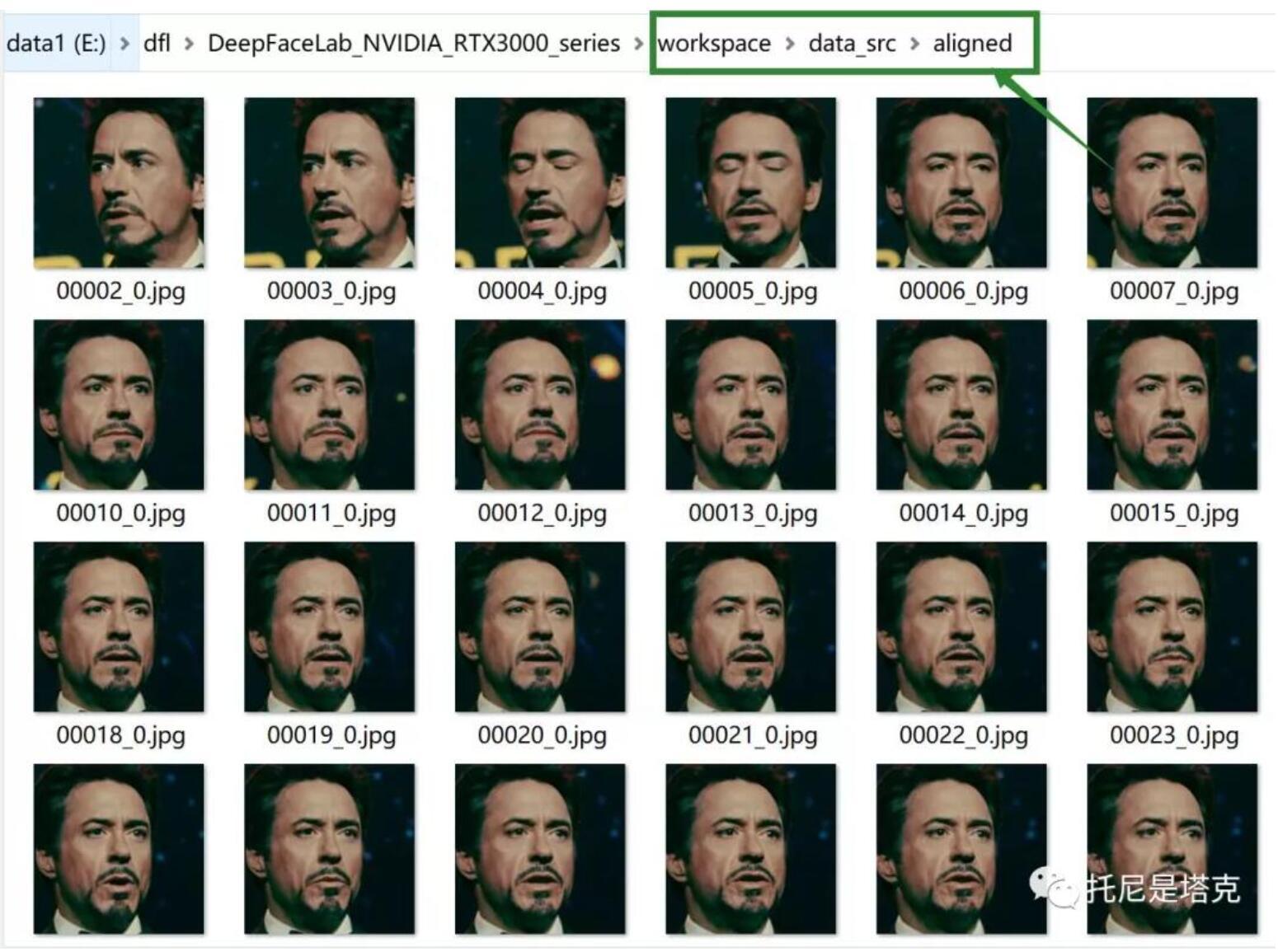
提取的头像保存在data_dst/aligned的文件夹里。
提取完之后也要对素材进行一个筛选。
把不是目标人物的素材删掉,把头像旋转的图片删掉。一般来说文件名后缀_1的都可以删掉。dst的删除核心原则是要换的人脸留下,不要换的统统删掉。
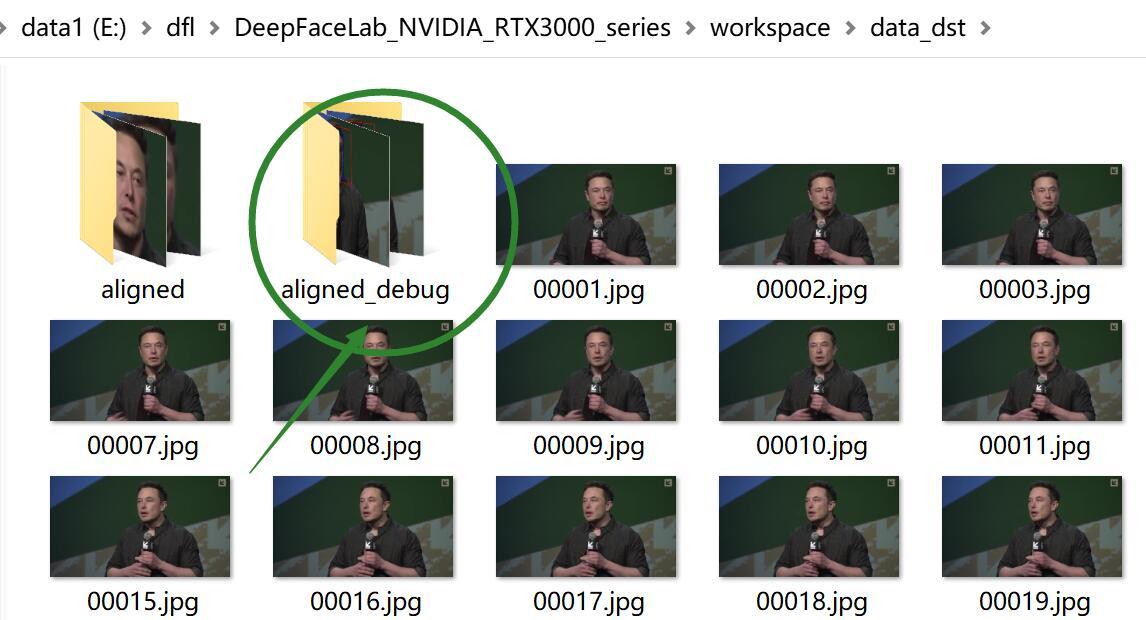
这些图标保存在aligned_debug里面
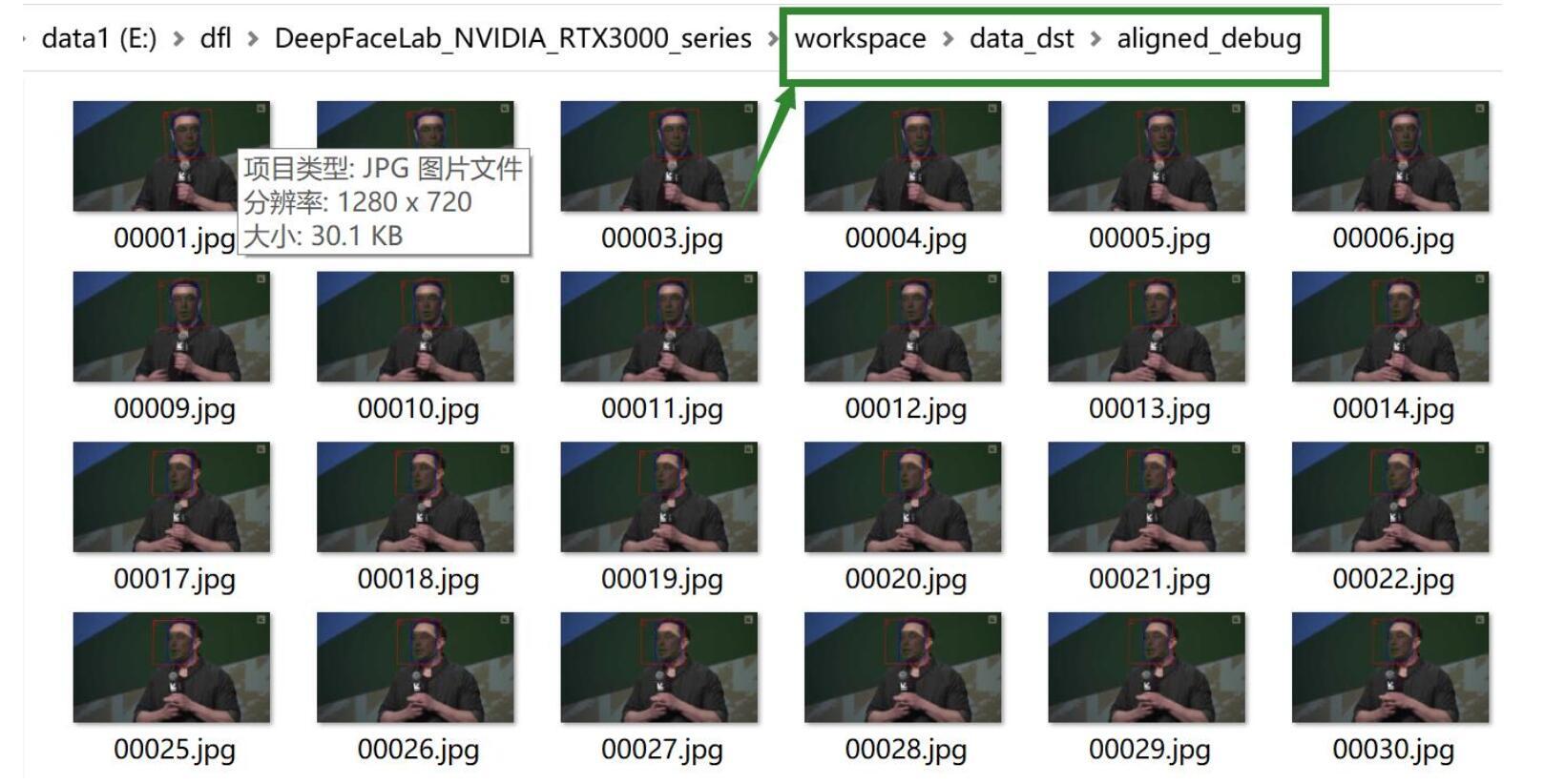
大概其中一张图片,可以看到人脸上有三种颜色的线框。

红色就是头像截取的区域,蓝色是面部区域,绿色是人脸轮廓,以及五官定位的点。其实就是人脸的landmark。通过debug你可以直观的看到人脸识别算法识别了哪些区域,有没有识别正确。
Step5:训练模型
双击批处理文件 训练轻量级模型 train Quick96.bat
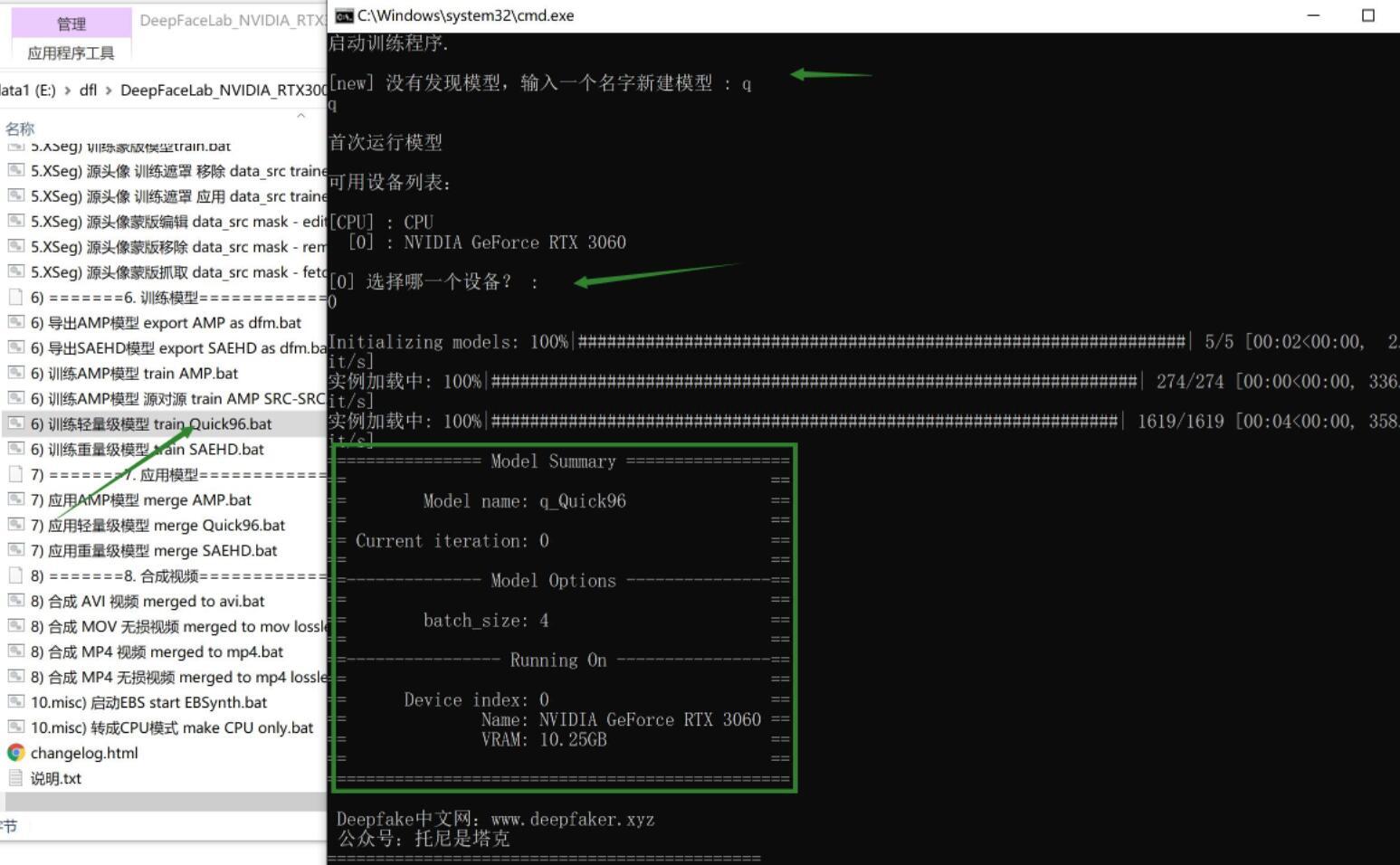
这一步是训练模型,所有步骤中最重要,最难,也是最耗时间的部分。目前新版本中主要包含三类模型,分别是Quick96,SAEHD,AMP 。
我把Quick96翻译为轻量级模型,优点是所需配置低,显存低,速度快,操作简单。缺点是不能自定义,像素比较低,合成效果差一些。
这个模型很简单,所以也非常适合拿来入门。所以本文就用这个来举例。SAEHD和AMP模型和模型训练的知识会另起一篇文章来介绍。
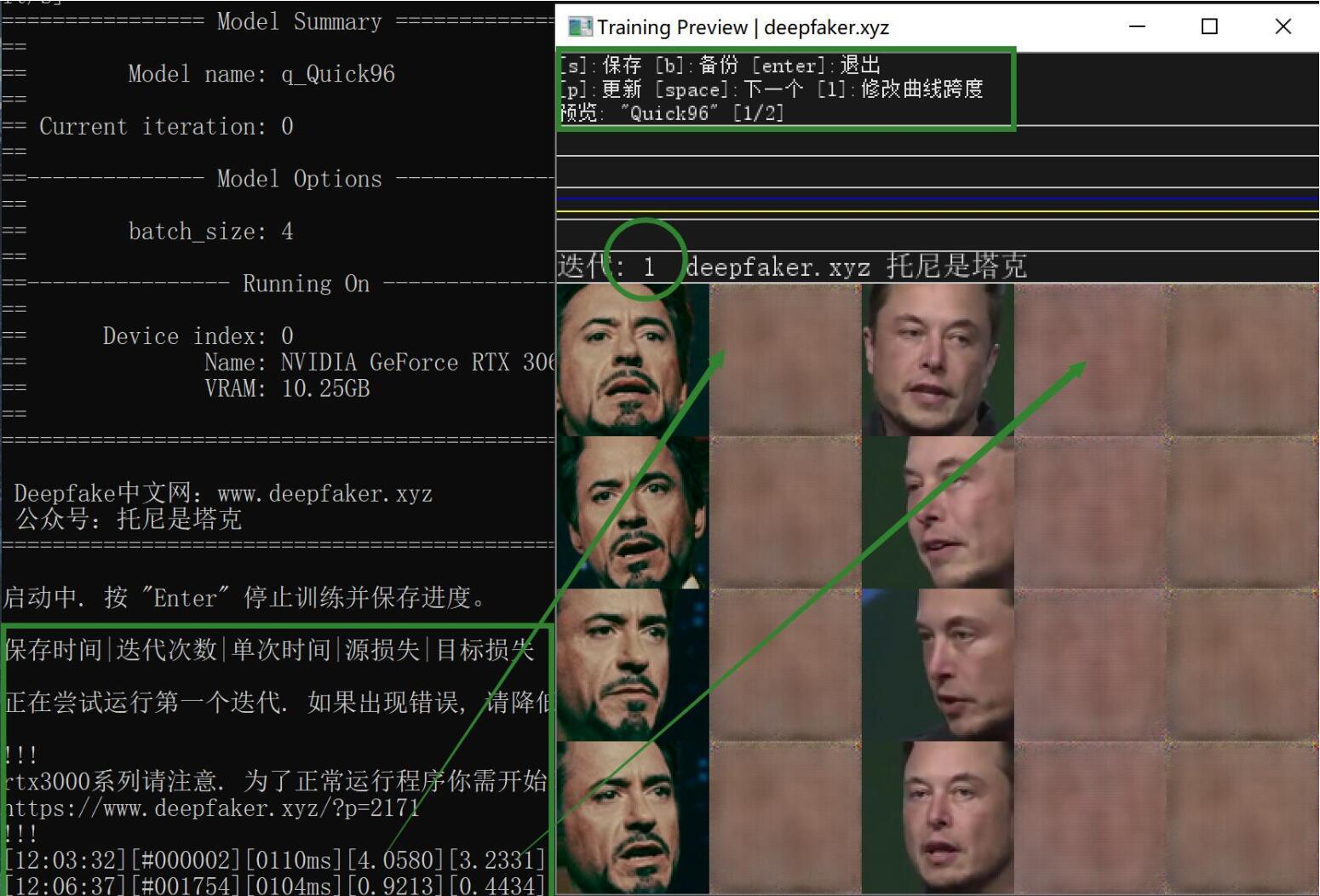
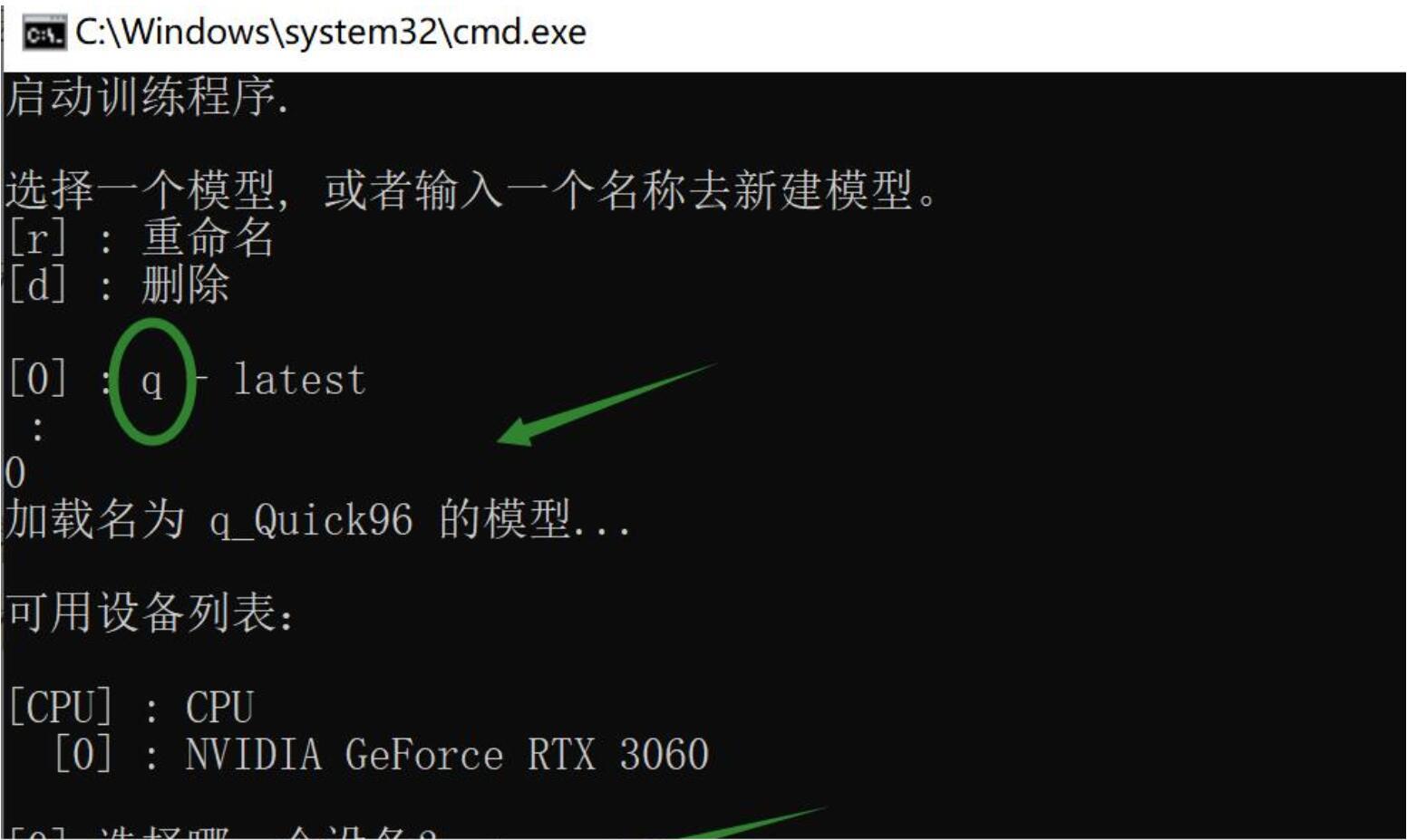
Quick96使用非常简单,双击批处理文件后,选择执行设备即可,这里一般都是选显卡,直接回车即可。设备选择完成之后,程序就会自动加载素材,并显示模型的参数,底部会有跳动的数字,然后会跳出一个预览窗口。
先来说说底部的数字,总共五列,分别代表:模型保存时间,迭代次数,单次迭代时间,源损失,目标损失。迭代次数是越多越好,损失是越低越好,零就是无损了嘛~不过,不可能达到!
下面来说说预览窗口
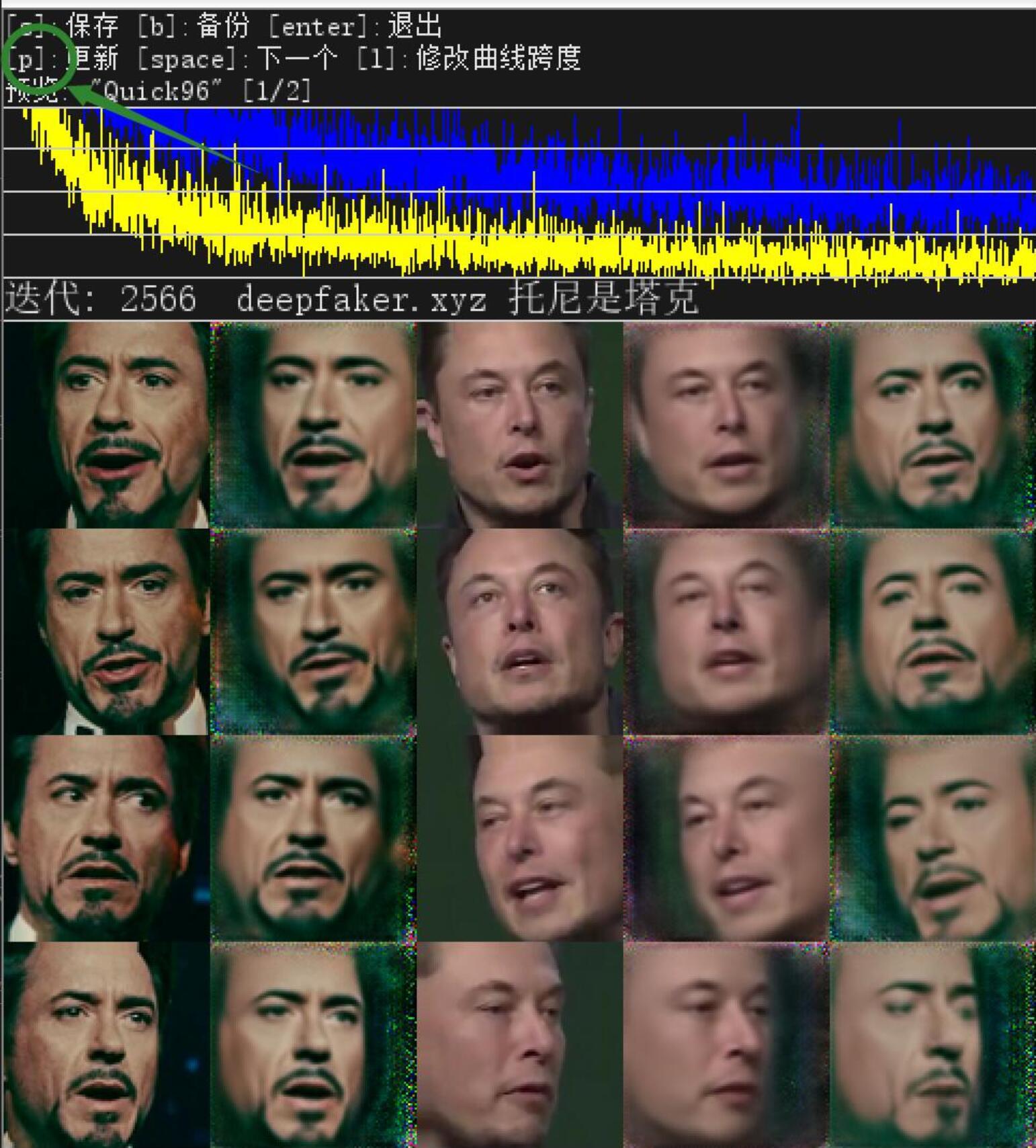
预览窗口包含操作提示、loss曲线,人脸区域。人脸区域总共五列。第一列是src,第三列是dst。第二,四,五列为算法生成列,刚开始是纯色,啥头像都没有。随着训练的进行,会慢慢出现轮廓,鼻子,眼睛,然后慢慢变清晰。
训练的过程就是等待这几列变清晰的过程,最后一列就是换脸后的效果。
这一个步骤并不会自动结束,需要自己判断,然后手动结束。可以通过损失值和预览图来进行判断。一般来说损失值(loss)值到了0.1x就差不多了。但是素材质量和数量不一样,会影响这个指标的变化速度。比如素材特别少,这个值降的特别快,特别低。图片不是很清晰,这个值也降的特别快,特别低。反过来,图片质量高,数量多,这个就很难降低。但是这样情况下训练出来的模型更好。
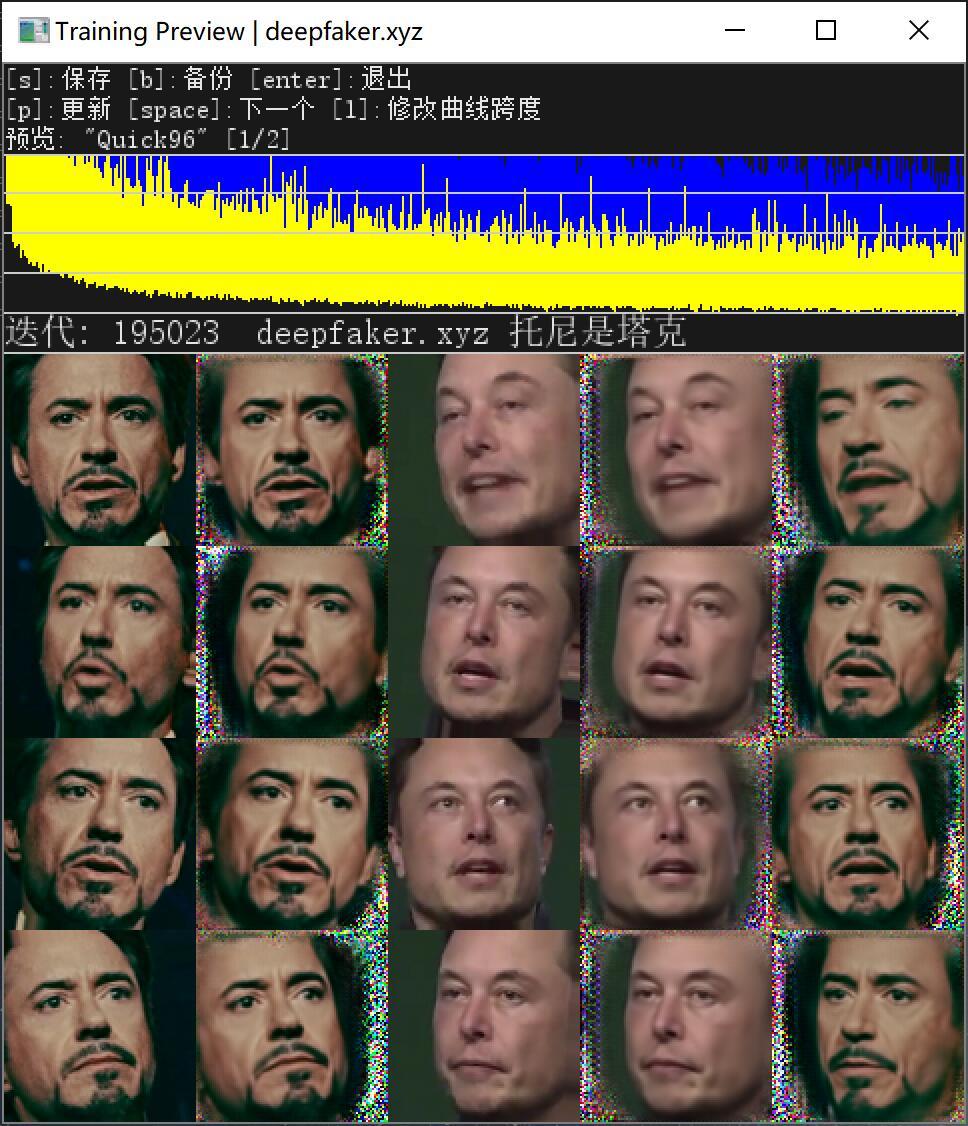
相比数字而已,通过预览图来判断就更加直观了。只要观察第二列是否无限接近第一列,第四列是否无限接近第三列。第五列的表情是否无限接近第四列。所有列的图片是否都足够清晰。如果答案是“Yes” ,那么按回车或者直接关闭窗口,进入下一步。
正常情况下模型会过几十分钟保存一次,也可以手动按S直接保存。关闭后,可以重新点击批处理文件继续训练,不用担心丢失进度。当然,要防止意外关机和重启,可能会损坏模型。
Step6:应用模型
双击批处理文件 应用轻量级模型 merge Quick96.bat
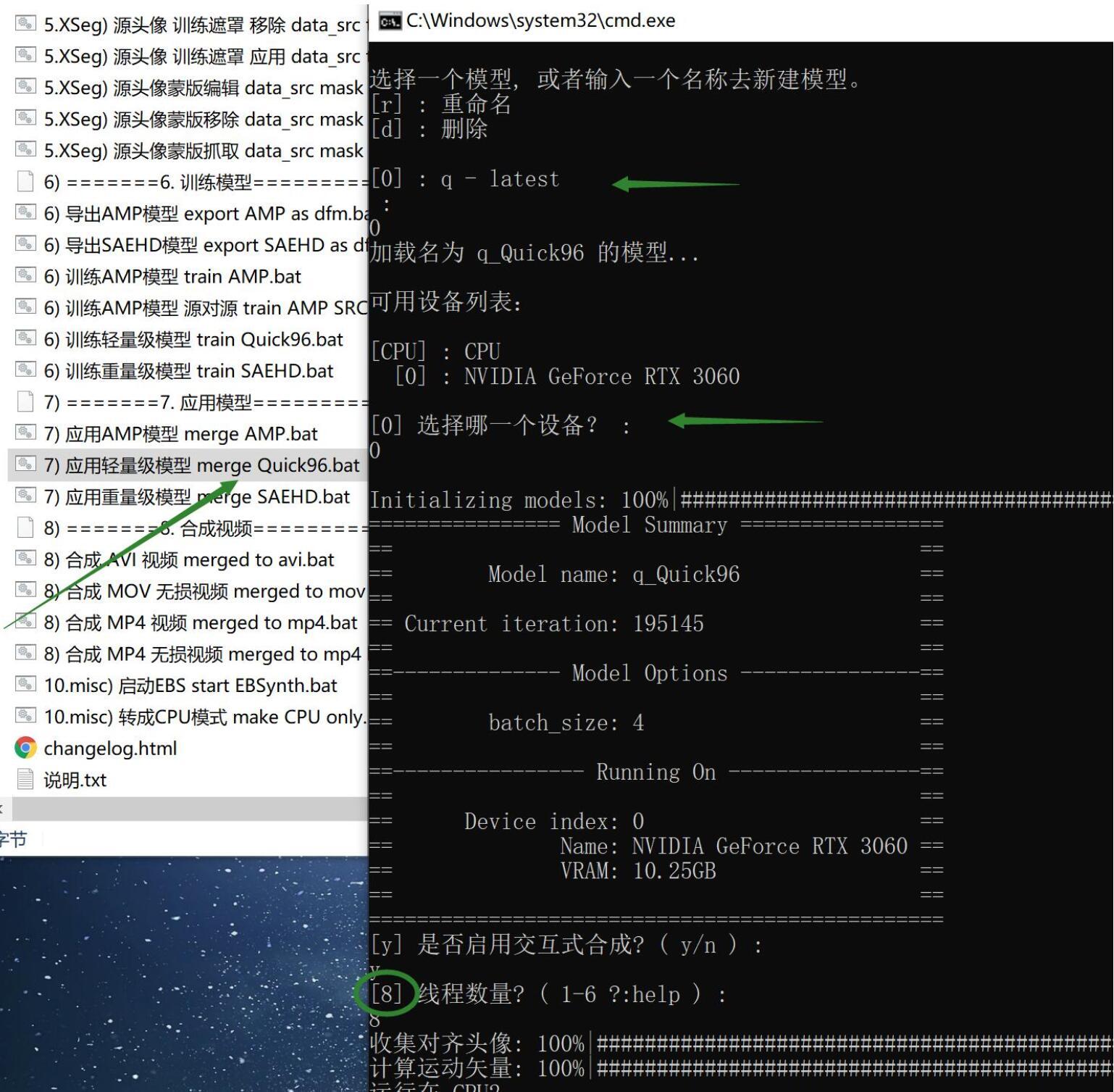
这个步骤要做的是将图片进行换脸。应用Quick96模型也很简单。启动直接按回车选中或者输入对应的数字选中上一步已经训练好的模型。然后软件就会加载模型并显示模型参数。
然后需要配置两个参数:
一个是是否启用交互模式,直接回车,默认启用。
一个是线程数量,输入小于等于8的数字,回车。注意,如果你核心特别多,默认回车会报错的!
稍等一会儿会弹出帮助界面。
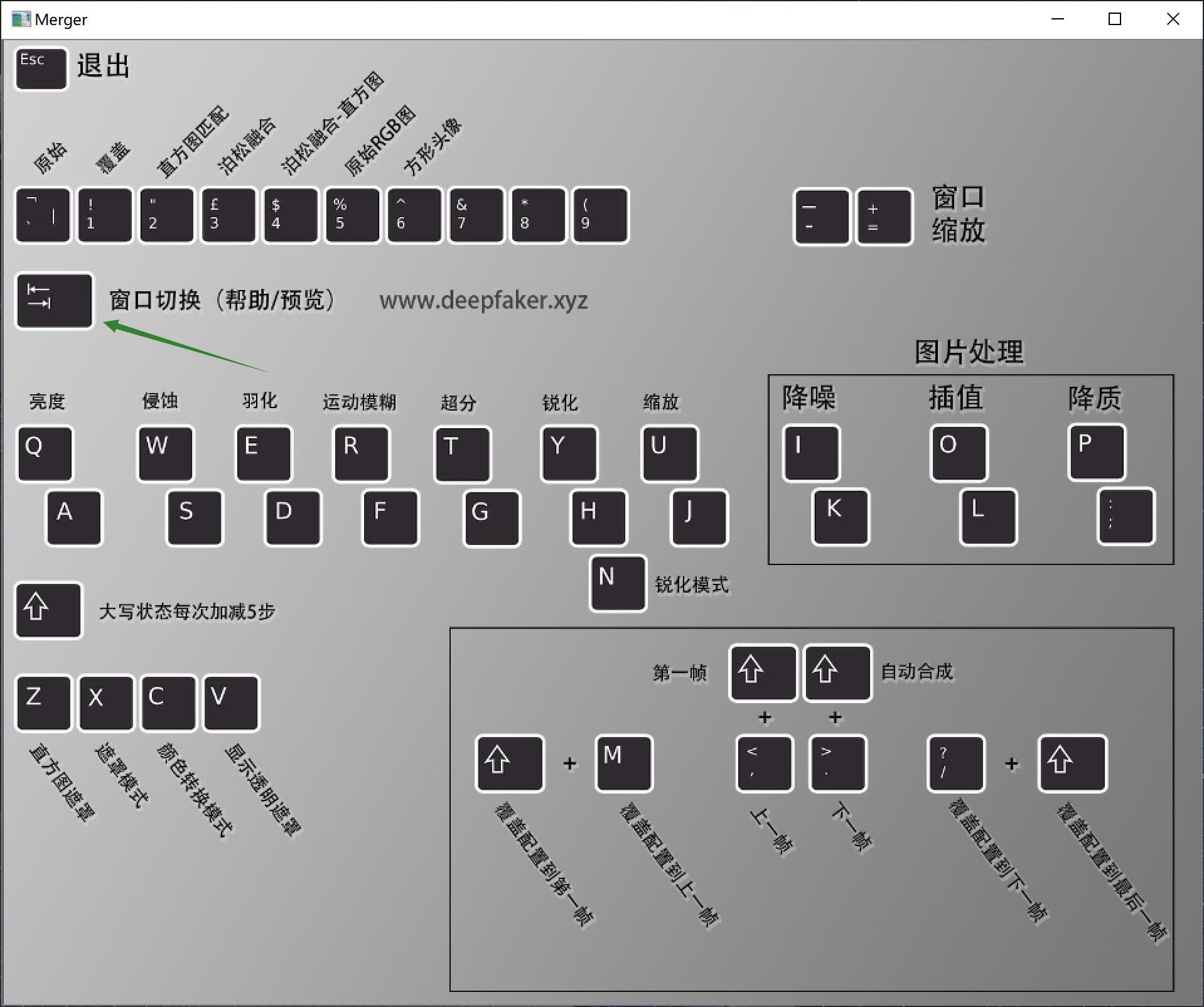
这个界面并没有任何功能上的用处,只是显示了这个环节可以使用的快捷键。每个快捷键旁边都有中文注释,可以看个大概,具体的参数含义我会在后面的文章中做一个详细的介绍。
点击这个界面,确保输入法为英文,按下键盘上的Tab,就可以进入合成预览界面

进来后,默认情况下都会有人皮面具的感觉,这是正常现象。因为我们参数还没有调整!就这个素材来说,只要调整W/S,E/D 快捷键即可。调整后的效果如下:

确认效果OK之后,按下快捷键shift+?(向后应用到所有帧) 然后再按下shift+>(自动合成) 就开始自动合成了。也可以通过键盘上的< 和 >进行手动切换,查看前后帧的合成效果。
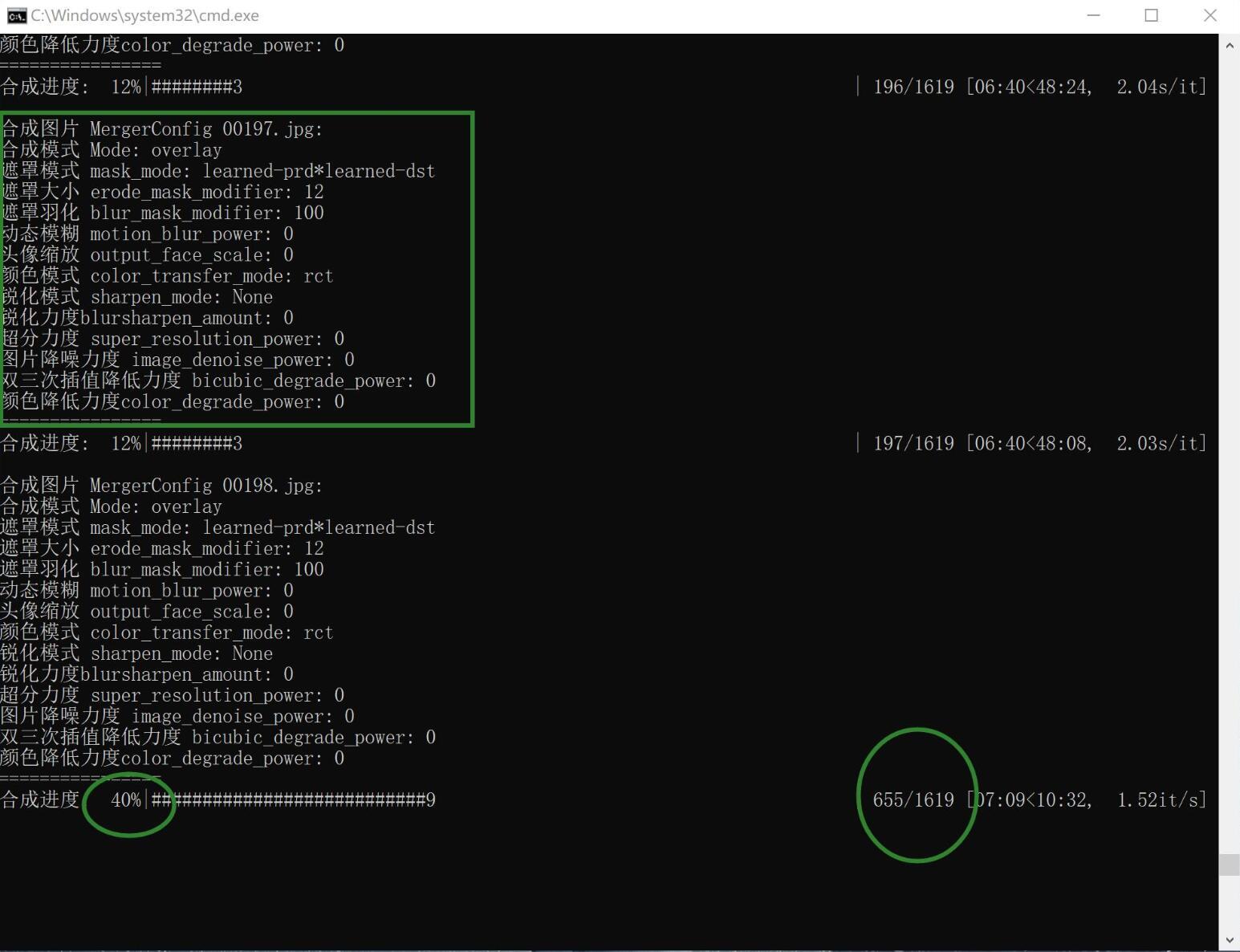
黑色窗口会显示所有的合成参数,并且显示进度条,等100%完成之后,手动关闭窗口即可。
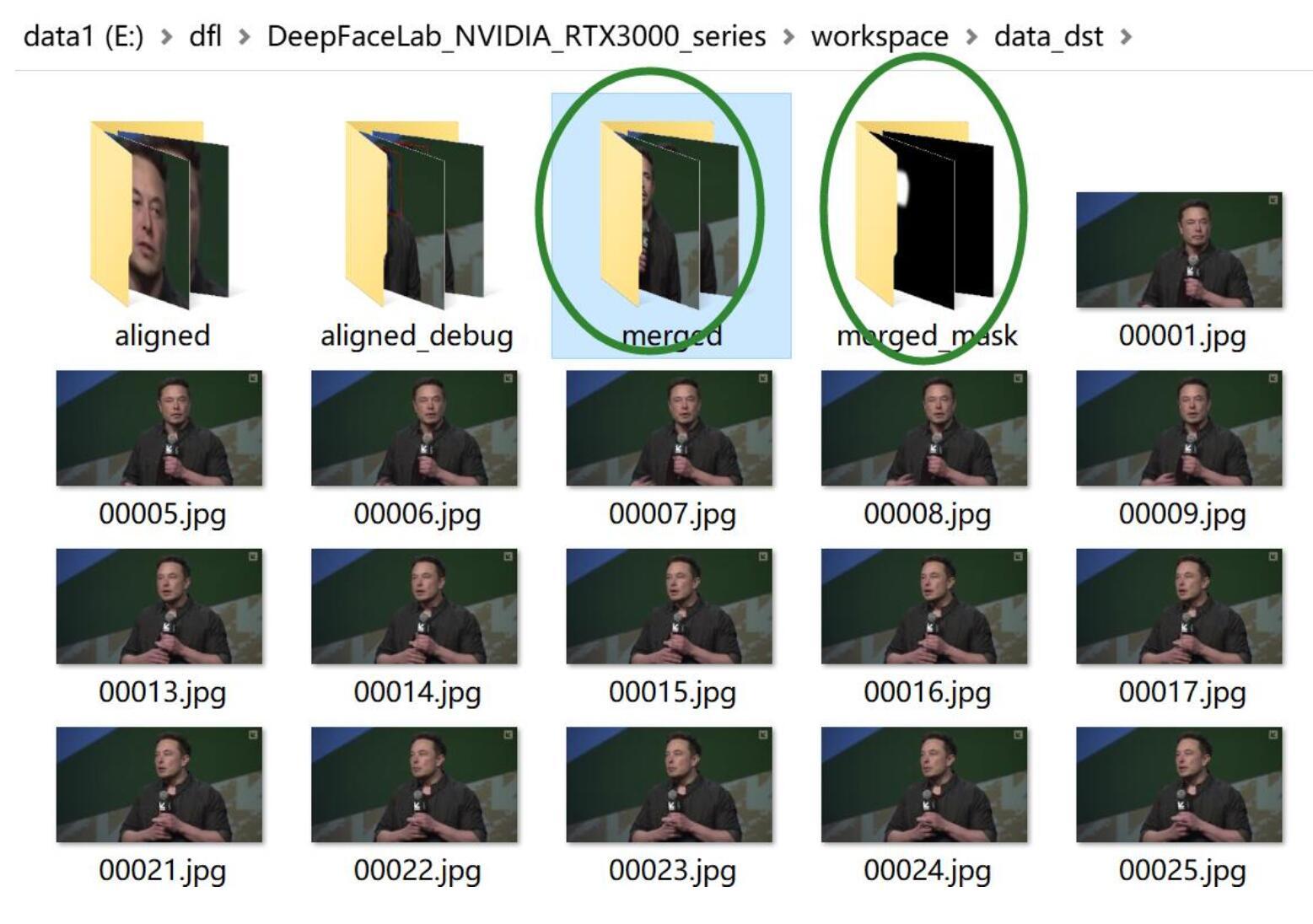
此时,在data_dst下面已经多了两个文件,一个是merged,一个是merged_mask

进入merged可以看到很多图,这些图片中的人脸已经完全换脸。
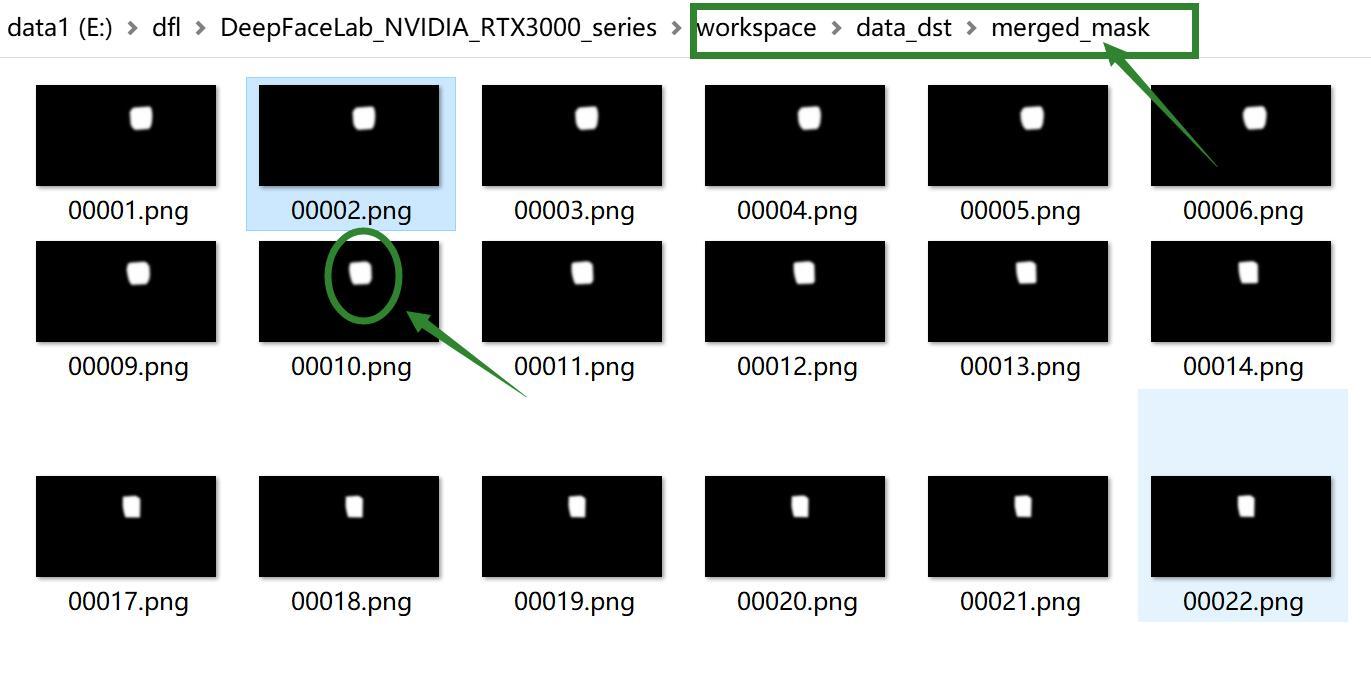
进入merged_mask可以看到一些黑色的图片,中间有一个白色的区域。这些文件是为了方便后期制作。我们单纯使用DFL的不用太关心。
Step7:合成视频
双击批处理文件 合成 MP4 视频 merged to mp4.bat
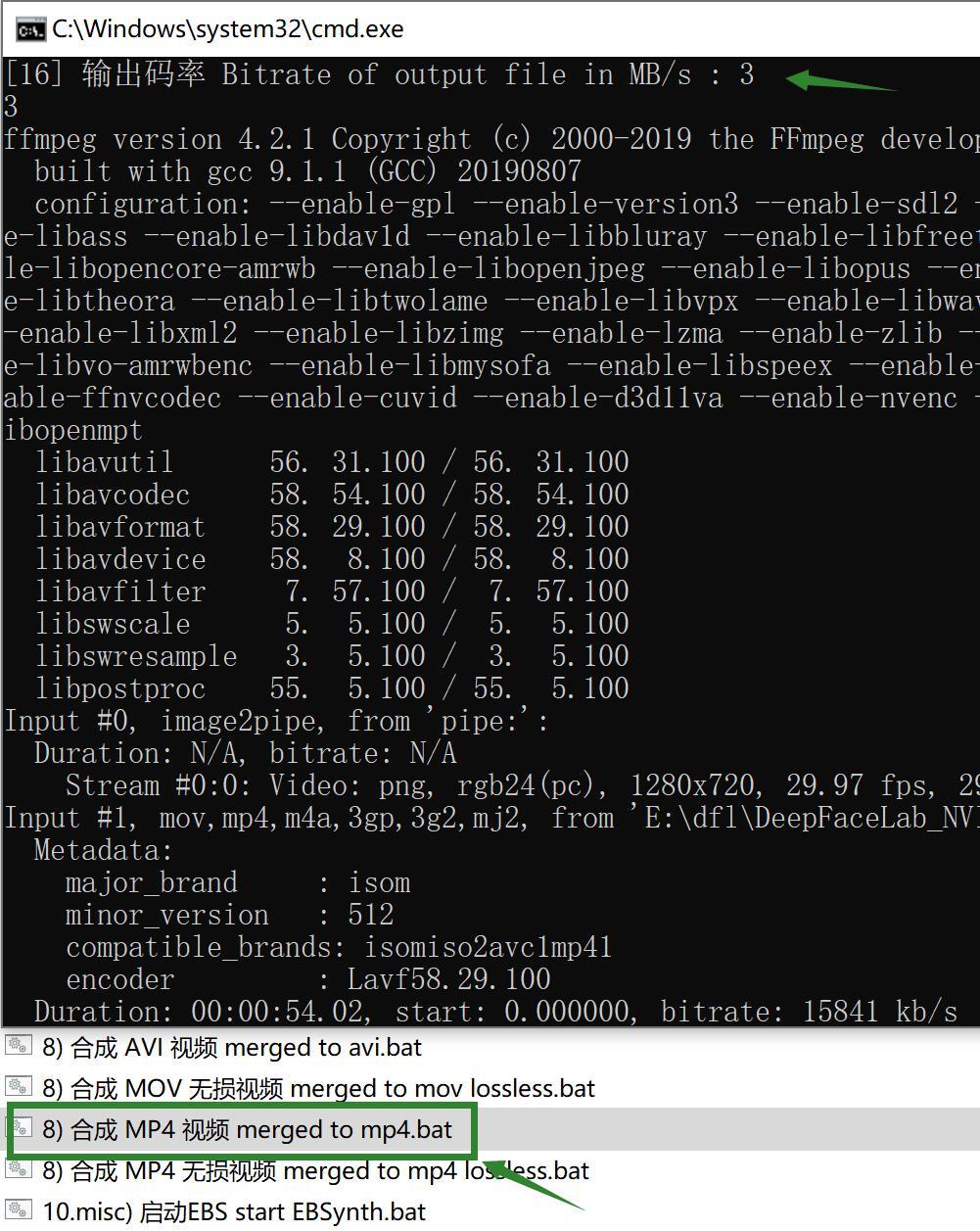
这个步骤是将已经换好脸的图片转换成视频,并且会自动读取源视频的配置信息,包括帧率,音轨这些。这个环节只有一个输出码率的参数,常规来说3就够了。
除了合成mp4之外,还可以合成无损视频,AVI ,MOV等格式,便于后期处理。
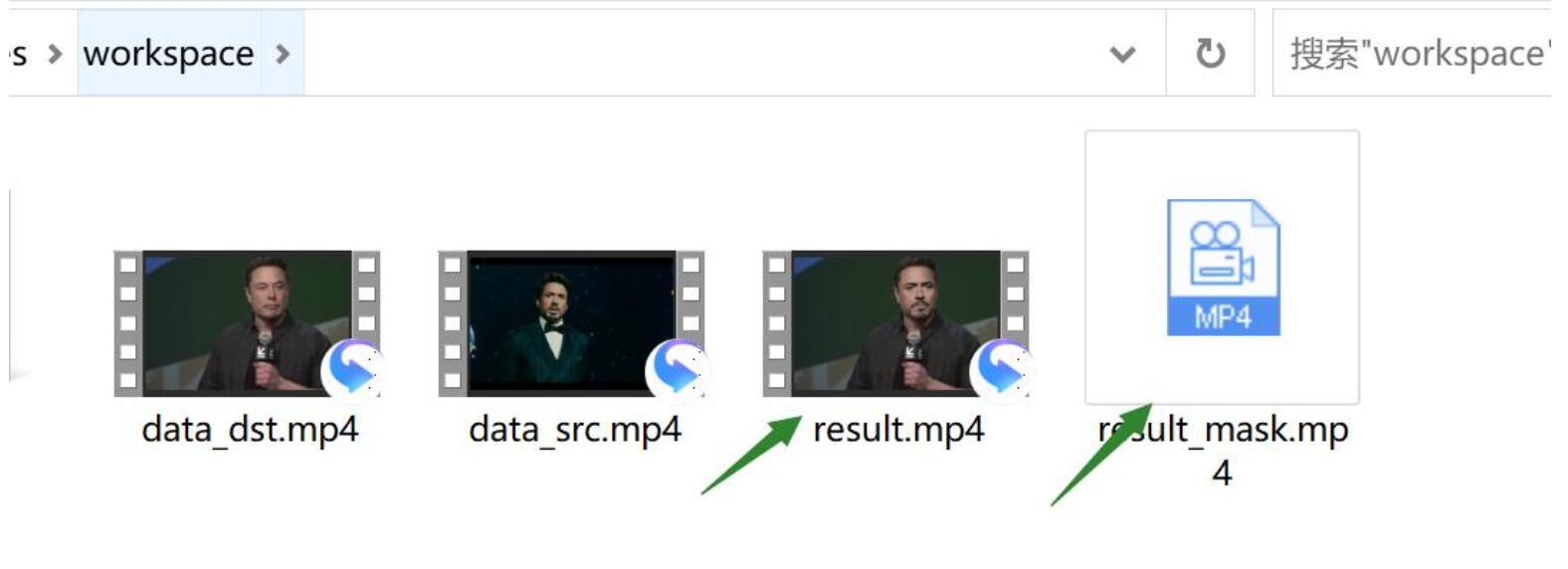
执行完成后,workspace下面多了两个文件,分别是result.mp4 和 result_mask.mp4 。前者就是我们需要的最终视频,后者是遮罩视频,供后期使用。
双击打开视频,就可以看到最终效果啦。
步骤其实不难,细节很多。有些是可以直接照搬别人经验的。有些需要自己不断摸索。这并不是什么傻瓜软件,要做出好的效果肯定是要花时间研究。就像即便送你PS,PR,你没有一定的学习积累不可能做出酷炫的效果。但是我可以保证,市面上几乎所有神乎其技的换脸视频都是基于DFL,有些可能专门准备了道具场景并使用了后期制作。
DeepFaceLab3系列


